
― Многие привыкли доверять рекомендациям программы. Но насколько в действительности точны ответы, которые предоставляет нейросеть?
― Ответы нейросети люди, как правило, слепо принимают за истину. Но никто не признается в том, что его модель работает не с точностью 100%, а всего лишь 60% или 80%. Нельзя слепо опираться на решения нейросетевых моделей. Вместо этого нужно учитывать то, насколько модель уверена в своем предсказании.
Допустим, модель определила класс опухоли и уверена в этом на 80%. На основе этого человек, который создает систему обработки ответа для дальнейшего внедрения в медицинский процесс, сам решает, достаточно ли этого уровня уверенности, чтобы принять решение о наличии болезни.
Врач, который использует программу по автоматическому распознаванию опухолей, тоже может посмотреть: «Ага, вот в этих пикселях изображения модель уверена на 90%, хорошо. А вот в другой области — гораздо меньше, поэтому лучше я перепроверю снимок вручную». Это позволяет медикам сэкономить время и сконцентрироваться на тех случаях, где опухоль не удается распознать с помощью нейросети.
― А как определить процент уверенности нейросети?
― В обычных нейросетях в качестве уверенности берется выход так называемого слоя softmax. Это функция, которая применяется в машинном обучении для задач классификации в случае, если классов больше двух. Она выдает вектор, который распределен по классам от 0 до 1. И этот вектор затем можно интерпретировать как некоторую уверенность сети.
Но с точки зрения математической статистики и теории вероятности некорректно принимать его значения в качестве уверенности. Например, мы можем проверить нейросеть и вместо опухоли показать изображение гориллы. Нейросеть, на основе функции softmax, скажет: «Это опухоль, я уверена в этом с вероятностью 10% или 20%». Но очевидно, что на изображении вообще не опухоль и даже не мозг. В идеале нейросеть должна ответить, что вероятность наличия опухоли 0%. Но с помощью функции softmax этого не добиться, поэтому ответы получаются некорректными.
Чтобы посчитать статистически правильную вероятность, можно использовать методы байесовского вывода для глубоких нейронных сетей и их аппроксимации (метод вычислений, при котором сложные математические функции заменяются похожими, но более простыми в описании).
Наталья Ханжина. Фото из личного архива собеседника
Это связано с понятием правдоподобия в математической статистике. При построении модели, обычно в качестве оптимизации используют метод максимального правдоподобия (MLE). И с точки зрения нейронных сетей правдоподобие является функцией потерь — она оценивает разницу между настоящим значением оцениваемого параметра и непосредственно самой оценкой, например, класса объекта и предсказанием модели. Отличие байесовских глубоких нейросетей от простых заключается в использовании метода апостериорного максимума вместо метода максимального правдоподобия при обучении моделей.
Что все это значит? Допустим, вы приехали в торговый центр на машине и оставили ее на парковке. А потом потеряли машину и пытаетесь ее найти. Если вы при этом пользуетесь методом максимального правдоподобия, то будете искать ее просто ряд за рядом: в одном нет, в другом тоже. Будете смотреть на соседние машины и сравнивать со своей: похожа ли, тот ли номер…
Если следовать методу апостериорного максимума, то в нем для оптимизации будет использоваться не только функция правдоподобия (это как раз наш способ сравнения машин с другими), но и еще некая априорная информация.
Например, вы точно помните, что оставили машину в определенном секторе парковки, так что будете искать ее именно там. И, соответственно, оптимизация (решение задачи) будет производиться с помощью не только функции правдоподобия (похожа ли ваша машина на другие), но и сектора, где она находится. Это уже называется метод апостериорного максимума — он работает на основе формулы Байеса,которая в целом в байесовской статистике является ключевым понятием.
― Что это за формула и как она используется при обучении нейросетей?
― Преподобный Томас Байес — священник и математик, еще в XVIII веке он придумал формулу, которая сейчас отчасти является основой статистики и машинного обучения. И она как раз про соотношение апостериорной и априорной информации, функции правдоподобия и распределения наблюдаемых данных. Но дело в том, что ее применение для глубоких нейронных сетей долгое время оставалось очень тяжелым с точки зрения вычислений.
Томас Байес. Источник: thedatascientist.com
Однако не так давно исследователи разработали инструменты, которые позволяют для глубоких сетей применять байесовские методы. Применение этих методов позволяет более эффективно оценить уверенность модели. Или, наоборот, ее неуверенность. В теории вероятностей эта неуверенность называется неопределенностью. Она бывает разных видов.
Есть неопределенность самой нейронной сети. Она может быть высокой в случае, если модели дали мало данных для обучения. Сетям, чтобы обучиться и при этом не переобучиться, нужно много данных. Чем больше выборка, тем она более репрезентативна. А если модели показать мало данных, то у нее будет высокая степень неопределенности при предсказаниях. И по мере увеличения количества данных эта степень будет уменьшаться. Такая неопределенность называется эпистемическая.
Второй тип неопределенности называется алеаторная, или алеаторическая, ее источником является какой-либо шум в данных. То есть когда, например, источником данных являются сенсоры, с которых снимали данные, и у них существует ошибка калибровки. Соответственно, это вносит шум в показания. Или, допустим, классы, которые нужно предсказать, сильно пересекаются между собой, нечеткое разделение. Все это тоже вносит алеаторную неопределенность.
Обычно данные для решения задач машинного обучения размечают люди. Те же снимки МРТ с опухолями — их размечают врачи. Но людям присущ человеческий фактор и они порой ошибаются. А ошибки в разметке тоже несут с собой алеаторную неопределенность.
Чтобы выводить и ту, и другую неопределенность, применяют вариационный вывод в сетях. И для вывода, например, эпистемической неопределенности были не так давно придуманы методы, которые позволяют делать очень просто и относительно быстро. Они основаны на технике dropout, направленной против переобучения нейросети.
― Как это работает?
― Сама по себе техника dropout состоит в случайном отключении нейронов сети во время обучения для предотвращения их ко-адаптации.
Давайте кроме того, чтобы использовать dropout во время тренировки, будем применять его еще и на этапе предсказания моделью. Мы будем каждый раз отключать случайные нейроны и получать немного другую модель. Допустим, мы сделаем это двадцать раз.
Получится ансамбль моделей. Затем на его основе выведем усредненные предсказания и измерим эпистемическую неопределенность. Она измеряется для задачи классификации, на основе метрики взаимной информации — mutual information. Соответственно, там, где mutual information наиболее высокая, те области изображения специалистам лучше изучить вручную.
Этот метод, с помощью которого сэмплируют модель, а потом усредняют предсказания, называется Monte Carlo Dropout.
Наряду с dropout, существует еще метод dropfilter, который отключает не нейроны, а целые сверточные фильтры в сверточных нейросетях. Мы думали, что никто, кроме нас, еще не додумался использовать его в манере Монте-Карло для измерения эпистемической неопределенности. Весну 2020 года мы посвятили экспериментам с Monte Carlo DropFilter, применяли его для нашей задачи распознавания опухолей мозга. И получили хорошие результаты — точность выросла на 3%, что значительно для нашей задачи, так как люди в ней борются за каждые полпроцента.
Initial image — изначальные изображения МРТ. Tumor Mask — маска опухоли, которую нейронная сеть должна научиться как можно точнее предсказывать. Whole tumor predicted — усредненные предсказания нейронной сети с помощью разработанного Натальей метода. Tumor uncertainty predicted — неуверенность сети. Изображение предоставлено Натальей Ханжиной.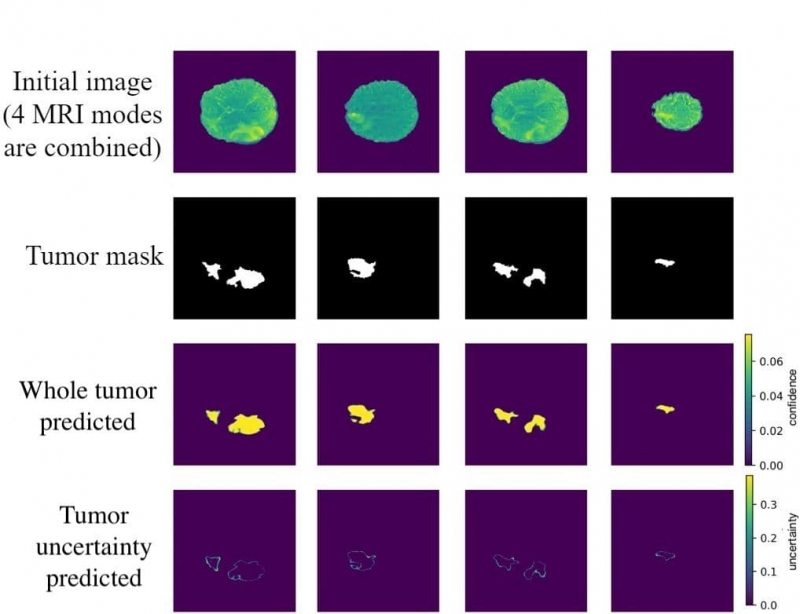
― Расскажите подробнее про вашу работу. Какой была реакция на исследование?
― Год назад мы послали нашу работу на главную конференцию в области обработки медицинских изображений и искусственного интеллекта ― MICCAI (The Medical Image Computing and Computer Assisted Intervention Society). Но в публикации нам отказали, поскольку примерно в то же время другие исследователи придумали тот же метод. А мы о них не знали — наши исследования вышли с разницей в несколько месяцев.
Поэтому в этом году мы решили переработать статью и написать не о новом методе, а о его применении на медицинских данных. Мы послали статью на другую конференцию — UAI (это главная конференция по неопределенности в искусственном интеллекте, которая до этого года имела ранг A*) и нашу работу приняли на воркшоп по прикладному применению байесовского моделирования. И в тот момент, когда я выступала на ней, мне пришло письмо с конференции МICCAI. На этот раз статью туда приняли, но для этого нам пришлось придумать совершенно новый метод оценки неопределенности.
― Что именно поменялось в методе исследования?
― За год мы провели эксперименты с разными методами, подобными dropout, но которые еще не были применены для оценки неопределенности. И в один момент я предложила взять за основу архитектуру NASNet — это одна из самых точных архитектур в области обработки изображений и классификации от Google.
Специально для этой сети была придумана техника ее регуляризации, подобная dropout — Scheduled DropPath. То есть вместо того чтобы отключать отдельные юниты, авторы предложили отключать целые пути в сверточных ячейках с увеличивающейся вероятностью дропа.
Поскольку это довольно эффективная сеть, мы решили применить ее для задачи распознавания опухолей. А потом технику регуляризации Scheduled DropPath использовали в Монте-Карло манере для оценки неопределенности. Улучшение составило 0,8% — это здорово, но для людей со стороны покажется просто статистической случайностью и удачей. Поэтому мы пошли дальше.
Дело в том, что у DropPath и dropout есть фиксированная вероятность дропа. Вместо того, чтобы фиксировать ее, мы стали искать наилучшую вероятность дропа, такую, чтобы она давала наибольшую точность распознавания. Можно, конечно, перебирать ее вручную — от 0 до 1 с определенным шагом, а можно искать с помощью оптимизации, так же, как обучаются нейронные сети. То есть сделать вероятности дропа обучаемыми. Этот метод, основанный на новом распределении, получил название Concrete dropout. Мы применили его для нашего исследования. И в итоге у нас получился новый метод Monte Carlo Concrete DropPath.
С помощью применения нового распределения нам удалось еще больше поднять точность сегментации опухолей и улучшить калибровку модели. Теперь она лучше справляется с оценкой неопределенности — калибровка модели стала лучше примерно в два раза, при этом точность стала выше на 3%. Этот метод для оценки эпистемической неопределенности работает лучше и точнее, чем подобные. Статьи выйдут в сборниках конференций: первая ― в CEUR Workshop Proceedings, а вторая ― в Lecture Notes in Computer Science.
― Как разработанный вами метод может быть применим на практике?
― Если говорить конкретно об этой задаче — учет неопределенности, мы внедрением не занимались, так как это область ответственности наших коллабораторов. Но чем лучше работает модель, тем точнее будут делаться предсказания нейросети при распознавании опухолей. Неопределенность, которую мы умеет предсказывать с помощью байесовских методов, при визуализации позволяет увидеть, где модель не уверена.
В целом, мой метод универсальный, он применим не только для этой задачи. Например, я использую его в своей диссертации, которая посвящена распознаванию изображений пыльцы растений аллергенов. Я разработала веб-сервис, основанный на глубоких нейронных сетях — с его помощью можно будет узнать о появлении аллергенов в городе.



