
The past defines the present
It’s impossible to make predictions without looking back on our past. For starters, it can be useful to see which of the previous forecasts have proven true – and to what extent. On the one hand, it helps us identify the basic patterns of technological development and the unresolved issues. On the other – to learn which prediction methods work and which ones don’t.
Let’s look at the timeline of the development of artificial intelligence:
1996: the first chess game between a human and a machine. The then-reigning world champion had faced off against IBM’s Deep Blue supercomputer. The machine wasn’t able to beat the human, but the experience allowed developers to identify the weaknesses and continue their research.
1997: a machine beats a human at chess. A year later, the game repeated – but this time, the machine won. It should be noted that the upgraded Deep Blue, despite its moniker, was only good at one thing: chess. This was a specialized system equipped with a massive database of chess moves that can’t be memorized by a human.
2000: a series of AI development forecasts. One of the era’s most prominent futurologists, Raymond Kurzweil, calculated that by the mid-2010s, the capacity of machines would equate the capacity of the human brain. By 2025, he claimed, technologies would emerge that are capable of imitating brain functions and possessing all of humanity’s knowledge. These predictions have come true only in part. The capacity threshold has been overcome, but scientists still haven’t managed to model the human brain – or even come close to the concept.
2013: the start of the modern AI era. One of the stepping stones for the development of today’s neural networks was the paper titled Efficient Estimation of Word Representations in Vector Space. Its authors had suggested a simple mathematical model for establishing connections between words and using it to train neural networks. Such an AI would be able to efficiently run even on low-capacity devices.
2016: neural network AlphaGo wins a game of Go against the reigning world champion. Just like Deep Blue, AlphaGo was designed to do only one thing. Still, it was already a complex neural network that, having played just a few rounds against the developers, began to play against itself. The system could “create” new combinations rather than calculate actions based on existing knowledge.
2017: neural network wins a game of DotA against the reigning world champion. What’s interesting about this case isn’t the win itself, but the speed with which the AI was developed. The bot played its first game in May – and by August it was able to outpace the planet’s strongest player.
2018: Attention Is All You Need is published. Authors of the paper presented a new AI model called Transformer. This publication paved the way for more complex, in-depth neural networks that can accurately capture and describe the semantics of not just individual words (like the simpler 2013 version) but entire swaths of text.
2020: the emergence of GPT (Generative Pretrained Transformer). This language model further solidified the principle of amplifying the efficiency of neural networks through increased computer capacity. It also produced the world’s first Copilot network, which provides suggestions on software code with high accuracy. Interestingly, the well-known ChatGPT would only emerge some time later.
2023: the release of the NVIDIA H100 graphics card. The capacity of ten such cards combined is near to the capacity of the human brain. It was now possible to develop a supercomputer as strong as the human brain and yet no larger than an office desk. Still, neural networks haven’t gained the ability to think.
At Roman Elizarov’s lecture as part of PI School, ITMO University. Photo by Dmitry Grigoryev / ITMO.NEWS
In the past 20 years, of course, some massive changes have occurred. But still, not everything the futurologists promised has come true. And, as the past shows us, solving a problem that appears to be the key to creating a brain-like network doesn't actually accomplish that goal. Complex technological development is crucial. This proves once again that each new stage of development brings about questions that scientists haven't even considered before. And as of today, plenty of such questions have accumulated.
The challenges of modern AI
Lack of consciousness. AI “knows” more than any person on Earth. But it uses this data much less efficiently than we do. As long as the architecture of neural networks doesn’t resemble that of the brain, it can’t begin to form thoughts. To create such an architecture, we don’t even need to know precisely how the brain works – a schematic would suffice. But for now, scientists don’t even have a concept of how such a network would work.
Note: one of the primary theories of consciousness is the attention schema theory. It proposes that how an organism reacts to external or internal information depends on several things:
receptors – these are the ways in which data is received and converted, either from external or internal sources, and transmitted through the nervous system into the brain;
world models – the collection of knowledge about the world, based on which the organism makes decisions about its actions;
body models – a similar collection of knowledge, but about oneself;
attention – the filter for incoming data that determines which information should be reacted to and which isn’t worth the resources. Attention is an organ that can be manipulated, just like hands or legs. This results in the creation of an internal attention model, which is consciousness within the parameters of the model.
AI developers encounter the most difficulty with imitating the mechanics of attention. Today’s robots, in most cases, constantly process all incoming data. Scientists are actively studying the way our brain manages attention, but a working schematic for the “mechanics” of attention has yet to be proposed.
At Roman Elizarov’s lecture as part of PI School, ITMO University. Photo by Dmitry Grigoryev / ITMO.NEWS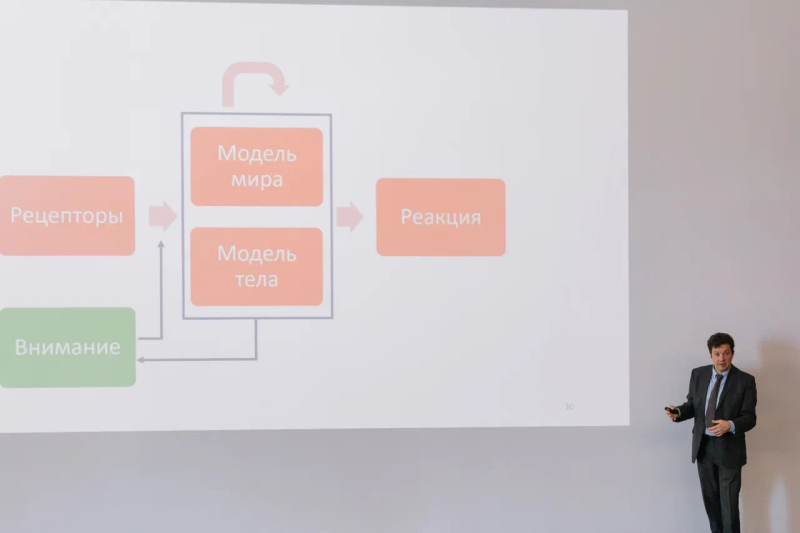
Resource capacity. Most often, AI these days is “upgraded” through increasing the computer capacity. At some point, it’s deemed to exceed that of the human brain. Still, these are very resource-consuming systems – creating, using, and training them can be very expensive. In such systems, all the capacity goes towards processing and “retaining” a massive array of data. This stress on the system could, too, be reduced through adding an attention element. Then, neural networks, just like people, would be able to analyze only the information that’s required to accomplish a specific task.
Versatility. Neural networks “know” everything about everything. But to solve a specific question, they must “reach” the relevant knowledge through the entire data array. As a consequence, this reduces their effectiveness and increases the cost. A solution to the problem is to train specialized neural networks. Existing training models can’t train an AI to “speak” to humans using only data from a specific field. Such knowledge doesn’t provide the volume, diversity, and context that are necessary to fully comprehend and generate natural language output. To create a flexible, adaptable AI, we must train it on large arrays of diverse data, allowing the models to generalize their knowledge and adapt to different scenarios.
Overall, any technology goes through a similar life cycle: innovation, heightened expectations, disappointment, widespread adoption. Right now, AI is in the “heightened expectations” phase. In the near future, we should expect one of the two outcomes: either a qualitative breakthrough and transition to a whole new level of development – or science will have to admit we’ve hit a ceiling with AI and interest towards neural networks will wane.
At Roman Elizarov’s lecture as part of PI School, ITMO University. Photo by Dmitry Grigoryev / ITMO.NEWS
What to expect from AI in the future
The past and present of neural networks allows us to put forth some ideas for how things could go next. These tendencies will be evident regardless of which scenario unfolds. Even if neural networks lose their hype, they’ll still be widely used to a higher or lesser extent.
Integration into human work. Despite our expectations, familiar professions aren’t going anywhere. But we will require less people to do the same amount of work. AI will help increase productivity, and that concerns not only copywriters and designers, but scientists and programmers, too – the latter to a lesser extent and much later. Right now, those who use neural networks aren’t that far ahead of the rest in terms of productivity. In the future, that divide will grow more evident and, in order to stay relevant, everyone will need to learn how to use neural networks. The same process occurred, for instance, with computers in the past.
More complex AI. Today’s neural networks are built according to simple mathematical models that don’t remotely resemble the human brain. But even now, AI is being made more efficient by expanding the models rather than just boosting the capacity. Models become more multi-layered and similar to the brain.
Technological development may slow down due to evolutionary and economical reasons. As long as human labor is cheaper than a robot, AI won’t be implemented on a massive scale. Besides, if humanity starts to see neural networks as a threat or an infringement on social and cultural norms, development will stall, as well.
A machine uprising isn’t going to happen. Not unless humans want it. By itself, AI can’t gain consciousness, much less freedom of will. For that, developers must themselves create a software architecture that provides such “options.” Thus, this wouldn’t be something that can happen by accident, but only as a result of intentional human actions.
Roman Elizarov has been working in his professional field for more than 20 years. For the past 25 years, he has been organizing student contests in competitive programming. For the past 20 years, he has taught at ITMO; he had worked at JetBrains for 7 years, including as Kotlin Project Lead. Currently, Roman is the head of Development Experience Department at Yandex. In June 2024, he joined ITMO’s PI School as one of the speakers. During this year’s course, the students learned to develop their 10-year professional development roadmap, improve their knowledge and skills based on the latest trends in science and business, and tried to forecast the technological development of the next few decades.




