
Igor Buzhinsky and Arseny Nerinovskiy, staff members of ITMO University’s International Laboratory "Computer Technologies", took 73rd place at the Jigsaw Multilingual Toxic Comment Classification competition, organized by Google’s tech incubator Jigsaw. Now in its third run, the competition tasks its participants with training an algorithm to detect toxic comments in a data array and sort them from neutral and positive ones. The participants from ITMO were placed onto the leaderboard’s silver category.
The event took place in spring and summer of 2020 on the popular online service Kaggle.com and involved over 1,500 teams from all over the world.
“The competition isn’t related to what I’ve been doing before this,” says Arseny Nerinovskiy. “Igor and I have previously worked together on an article; we had some free time and decided to enter a Kaggle tournament. We picked this one because it allowed us to train “transformer” networks, which are very resource-hungry. In our daily life, we wouldn’t have access to this kind of power, but Kaggle provides free access to computational equipment, so we decided to give it a try.”

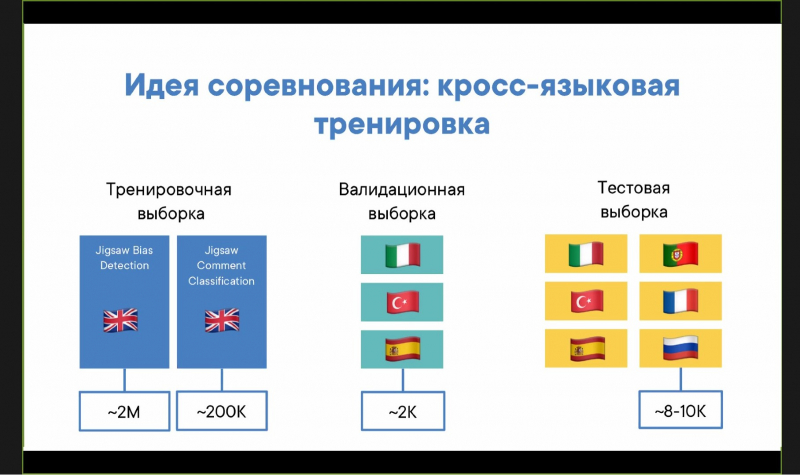
“Transformers are a type of neural network that was proposed in a 2017 article titled Attention Is All You Need,” says Ivan Smetannikov, an associate professor at ITMO University’s Information Technologies and Programming Faculty. “Essentially, they solve the issue of encoding-decoding and, for one, can be effectively used in computer translation. One of the features of the competition was that training sets were in English, but the validation and test sets were in other languages. This and other aspects of the competition called for the use of such models.”
Training the network
The participating teams had over two months to develop their solution. As training material, they were provided data from the previous competitions – around two million English-language comments for training and 8,000 comments in three languages for validation. These comments were marked as toxic or non-toxic in advance. After working through one or another hypothesis, the participants would check their algorithm using the test set, also provided by the organizing team. The test set consisted of 60,000 comments in six languages. This, too, contained toxic and non-toxic comments, though these were no longer marked as such. The results of the testing were submitted to the organizers, who conducted automated assessment and added points to the scoreboard.
“The thing is, in a multilingual context, it’s easy to collect a set in one language. But to produce many sets in several languages is difficult,” explains Arseny Nerinovskiy. “Let’s say it’s easy to put together a Russian-language set from a Russian social network; but it’s harder to do the same for the Ukranian and Kazakh language, as it is harder to find people writing in those languages on the website. That’s why such a set-up – training in one language and then putting the algorithm to work in many – is so popular.”
A neural network is trained in two stages. First, there’s pre-training, when its creators load it with a massive amount of texts written in various languages. There is but one condition: it must all be coherent text written by actual humans.

“In these texts, you may sometimes skip random words and the model has to learn to predict them. That’s how it’s able to understand the logic of language. Then begins training, which is when you teach the model to find toxic comments; those are discerned from non-toxic ones partially through this “understanding” of a language’s logic that was acquired during pre-training,” explains Arseny Nerinovskiy.
Now, the neural network is ready to look for toxic comments not only in the language of its initial tests, but others as well.
“There really isn’t anything surprising about this; if you think about it, all people on the planet think in similar ways regardless of which language they speak,” says Ivan Smetannikov. “Languages may differ greatly, but in the end, the meaning is the same. Of course, such a statement may be crude, as there are also such aspects as cultural context, connotations, and many linguistic traits of the specific languages, but the general idea is clear. In some sense, this quality is exploited by the transfer learning method, in which we train the model in one language and then train it a little more and use it in a different language. This technique is usually employed when you have lots of processed text volumes in the donor language and nearly none in the recipient language.”
Path to silver
The participants were not subject to any limitations. They could choose any transformer and train it using any set – not even necessarily the one provided by the organizing team. Participants were able to freely seek out information on their task in research articles or by getting in touch with companies. Moreover, they also had access to a message board where they could discuss various approaches right during the tournament.

Even though this was the ITMO team’s first time at the competition, it quickly rose into the silver section of the leaderboard, in which the top 5% of the teams are located.
“Transformers are heavily dependent on how their training started and in which order the data was fed to them,” says Arseny Nerinovskiy of one of the methods that helped them produce great results. “We trained a model several times from the same starting point and then combined all its iterations. It’s a simple approach, but we believe it has earned us some bonus points by making the transformer more stable.”
Some participants translated the sets received from the organizers from English into other languages using computer translation methods. The two participants from ITMO, too, employed this approach, but exercised carefulness.
“There’s the issue of detoxification – a toxic English comment, when translated into Russian, becomes much less toxic. Such is the nature of modern translation software,” explains Arseny Nerinovskiy. “We put less focus on translations. When we used translated data, only one model was successful.”
At the same time, say the researchers, they participated in the competition in their free time when not studying or doing research, so they are quite satisfied with the results.
“I was writing my Master’s thesis. Igor was working on an article,” says Arseny Nerinovskiy. “In total, we submitted some 96 result sets. Those in the top 10 of the leaderboard submitted between 300 to 400.”
Arseny Nerinovskiy presented the results of the competition and described the experience he gained there during the online meetup VK Tech Talks ITMO.





