
В этот раз темой встречи стали большие данные и то, как они используются учеными в их исследованиях. Science Slam Big Data организован Высшей школой менеджмента СПбГУ и петербургской медиакомпанией «Бумага»*.
В мероприятии поучаствовала и аспирантка Ксения Балабаева — инженер-исследователь научной группы «Цифровое здравоохранение» национального центра когнитивных разработок Университета ИТМО. Ее рассказ о том, как машинное обучение можно использовать для прогнозирования развития заболеваний и как корректно извлекать информацию из медицинских карт пациента, зрители посчитали одним из двух лучших выступлений — наравне с докладом известного урбаниста, руководителя подразделения исследований компании Habidatum и сотрудника кафедры социально-экономической географии зарубежных стран МГУ Руслана Дохова. В итоге они оба стали победителями.
«До этого я сама несколько раз наблюдала из зала за выступлениями молодых ученых — это показалось веселым и интересным, стало любопытно представить себя на их месте. Плюс во время подготовки идет довольно плотная работа с экспертом по публичным выступлениям — думаю, этот опыт пригодится и на научных конференциях, позволит сделать доклады менее занудными и более понятными даже для неподготовленной аудитории.
На прогоне перед трансляцией участники увидели выступления друг друга, и тогда я поняла, что все довольно много сил потратили на это, и все доклады получились интересные. Поэтому никакого предвкушения победы не было, и результаты приятно удивили», — делится впечатлениями Ксения Балабаева.

Также доклад представила Алина Владимирова, научный сотрудник Центра Юго-Восточной Азии, Австралии и Океании Института востоковедения РАН — она рассказала о том, как с большими данными работают историки. Кроме того, с докладом выступил Дмитрий Скугаревский, ассоциированный профессор ПАО «МТС» по эмпирико-правовым исследованиям Европейского университета в Санкт-Петербурге — он показал результаты исследования денежных переводов заключенным России по системе ФСИН Деньги. А Владимир Горовой, Data Science Product Manager в «Яндекс.Вертикалях», старший преподаватель кафедры информационных технологий в менеджменте Высшей школы менеджмента, в докладе представил алгоритм сортировки объявлений о сдаче и продаже квартир по качеству ремонта на фотографиях.
Рассказываем про доклады победителей, а также других участников Science Slam Big Data.
Как электронные медкарты помогают прогнозировать болезни
Многие люди — если не все — хотели бы заранее знать обо всех рисках развития у них того или иного заболевания. Такие методики, вроде ДНК-анализа, уже существуют — но из-за высокой стоимости доступны они далеко не всем. Существует и другой способ — построение моделей на основе данных из медкарты пациента. Приходя на прием, вы рассказываете о себе много информации, в том числе о своих прошлых заболеваниях, вредных привычках, аллергиях и так далее. Часто врачи просят пациентов подробно рассказать и о заболеваниях ближайших родственников — все это может быть использовано для предсказания появления каких-либо проблем со здоровьем в будущем.
Однако читать и анализировать истории сотен пациентов — довольно сложная задача. И здесь на помощь приходят алгоритмы работы с большими данными. На основе данных из медкарт исследователи могут строить модели, которые будут сами рассчитывать взаимосвязи, оценивать риск развития заболеваний, составлять прогнозы лечения и подбирать не конфликтующие медикаменты.

Как разрабатывают такие модели? Вся информация из анамнеза фиксируется в виде текста — и именно в таком виде с ней работают исследователи. Задача — найти в этом тексте релевантные данные, например, конкретные события в жизни пациента. Все это можно сделать с помощью ключевых слов, но проблема в том, что поиск по словам не сработает, если названия болезней в тексте написаны с ошибкой. Еще не совсем понятно, как быть, если упоминаемая в рассказе болезнь отрицается, а не утверждается? А еще надо отфильтровать ту информацию, которая относится к самому пациенту, от той, которую он рассказывает про своих родственников.
Пожалуй, самая понятная задача — это автоматическое исправление ошибок и опечаток. Для этого используется алгоритм на основе принципа расстояния Дамерау-Левенштейна. Этот метод позволяет оценить, сколько изменений нужно произвести в слове с опечаткой, чтобы получить его правильное написание. Тут появляется еще одна задача — разработать нейросеть, которая будет учитывать смысл слов и корректно заменять их. В качестве подсказки выступает контекст: мы можем посмотреть, какие слова встречаются рядом со словом, например, «поджелудочная железа». Это может быть «опухоль», «язва», «болезнь», «боль», «рак» и так далее. Чтобы это сделать, нужно собрать большой корпус текстов, в которых все слова написаны правильно и без ошибок, и на основе этого текста обучить языковую модель.

Задачу отделения фактов о пациенте от фактов о его родственниках решается в два этапа. Сначала используется бинарная классификация, которая кластеризует кусочки данных на две группы: относящиеся к пациенту и не относящиеся к нему. Затем производится уже более сложный процесс мультиклассификации с учетом всех наименований родственных связей. С помощью этого же алгоритма можно построить дерево наследственных заболеваний, которое также участвует в нашей предсказательной модели. После всех этих манипуляций получается очищенный и подготовленный текст, который может быть автоматически проанализирован алгоритмом и использован в построении предсказательной модели.
Как большие данные позволяют строить города для комфортной жизни
Руслан Дохов рассказал о том, как урбанисты используют большие данные. Ошибки городского планирования часто обходятся очень дорого: истории известен ряд случаев, когда на строительство новых микрорайонов или городов-спутников тратились миллионы долларов, но в итоге в них никто не стал жить.
Как же сделать так, чтобы новые районы принимались существующими городскими системами? И как заранее разработать такой план, который точно сработает? За последнее столетие накопилось много знаний о том, как устроены городские системы. Все они обладают двумя основными свойствами: пространственная упорядоченность и иерархичность.
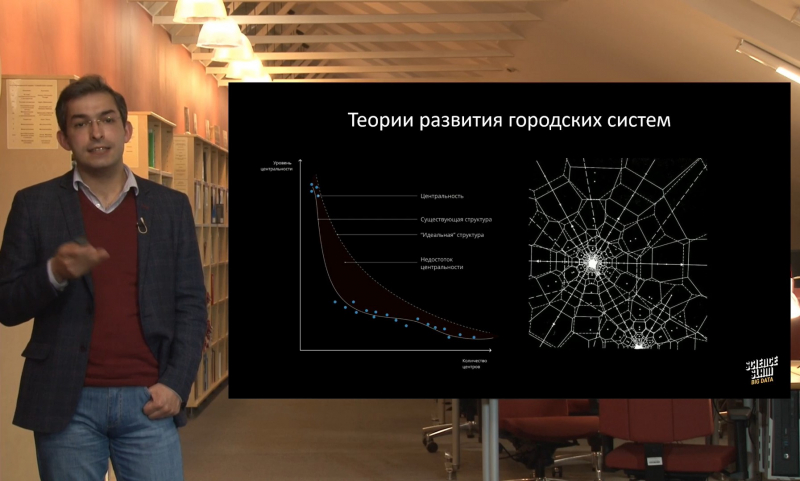
Городские центры и зоны тяготения между ними расположены не случайным образом — мы можем точно прогнозировать, где, вероятнее всего, они возникнут. Для этого в настоящее время используется большое количество данных: передвижения жителей, которые отслеживаются по GPS, семантические данные о мнениях жителей (сообщения в соцсетях, СМИ, опросы), данные о рынке недвижимости, данные о покупательной активности, параметры физической среды (качество воздуха и уровень загрязнения). Но с ними есть некоторые проблемы — эти данные не собираются по валидированным методикам, а производятся в результате деятельности других систем. Поэтому на первом этапе нужно отфильтровать большой шум и оставить только то, что будет иметь информационную ценность — то есть выделить аналитические индикаторы.
Главный индикатор — это так называемая «центральность». Чтобы ее количественно измерить, в исследовательской команде Habidatum придумали формулу, которая учитывает разнообразие мест в конкретном районе, количество людей, которые в этих местах бывают, и уровень потребления в этих местах (по базе банковских транзакций). На основе данной формулы можно четко определить иерархичность районов и принять те меры, которые эту иерархичность сгладят.
В принципе это и является основной задачей городского развития: либо дотянуть существующие центральности, прибавив им функций (например, построив дополнительную инфраструктуру), или же создать новые центральности на периферии.
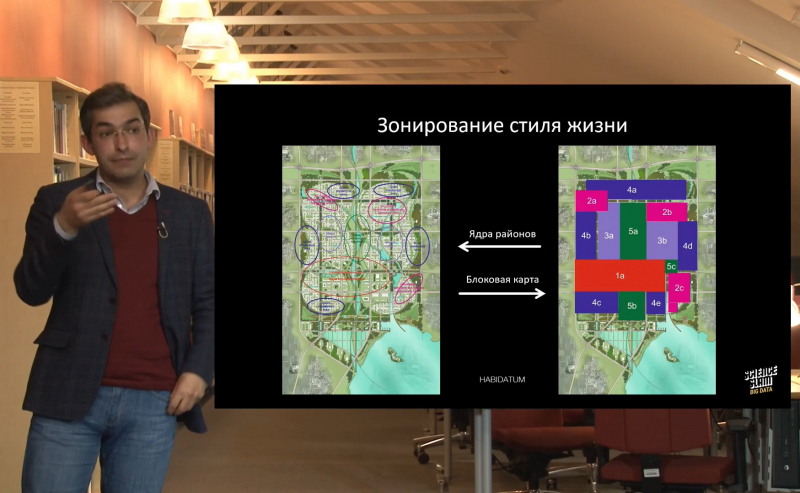
Например, в Китае действует пятилетний план урбанизации. Его цель — разгрузить Пекин и построить вокруг него несколько небольших городов на 500 тысяч человек. Сейчас на месте стройки — только чистое поле, но власти Китая хотят примерно представлять, как будет выглядеть построенный город через 50 лет. Для этого исследовательской группой Habidatum было разработано примерное зонирование районов по типу и плотности городской активности в течение суток: деловой центр, вторичные городские центры, тихие резидентные зоны, рекреационные зоны и зоны смешанного использования. После этого для каждого типа зон были подобраны такие же зоны-аналоги в существующих городах Китая, Юго-Восточной Азии, а также деловой центр Сиэтла (США). Эти примеры использовались для обучения алгоритма — чтобы он посмотрел на пространственно-временные ритмы в этих городах и сгенерировал на их основе еще несуществующие районы. Алгоритм рассчитывает, какая плотность людей будет в конкретном участке в конкретное время, и составляет пространственно-временные фигуры. На ее основе мы можем предсказать, где будут основные концентрации людей, а значит, куда притягиваются бизнесы и где нужна специальная архитектура.
Полное видео выступлений можно посмотреть по ссылке.
*Средство массовой информации, признанное «иностранным агентом»




