
In your lecture you spoke of theoretical models that are based on past experience but don’t use data. Why are such models valued in science?
It’s simple. Nowadays, data science and Big Data are largely trends, and the interest in these topics is reliant less on the nature of an inquiry than the desire to keep up with the times. Many methods that we use today have existed 10 or 20 years ago, and we’re just giving them new names. Neural networks and neural trees were invented back in the 1960s, but they were soon forgotten because we just didn’t have any computers capable of handling them. Yet the methods still evolved. It was fairly recently that computers and software became powerful enough to make these methods viable. One popular example is Google’s deep learning system that tells apart pictures of cats and dogs. To train such a model, you’d need plenty of data; such databases just didn’t exist back then, and now that they do, we see a growing interest in such methods.
At their core is the idea that we have data from which we need to extract as much information as possible. The issue is that the data can be faulty, incorrect or inaccurate. Data can also show correlation, but we can’t use it to establish cause-and-effect. To understand the latter, we need to know which mechanisms have produced this data. That’s why we need models. The “data-free” models are theoretical models that stem not from any specific data, but from the experience and knowledge humanity has acquired, and these models can be built.
The classic model of an infectious disease (the Kermack–McKendrick theory) was established in 1927. It was theoretical and based on simple principles: the more people are infected, the more people are likely to catch the disease, and the more people catch the disease, the more there are infected. The theory is based on very simple rules, but not any specific data; it’s purely theoretical. Once we do acquire new data, we already have a model, and we use it to connect data from various sources. One particular thing we do is use agent-based models, which are a type of theoretical models.
Where does agent-based modeling stand among other methods used in social modeling (statistical models, Markov models, and system dynamics models)?
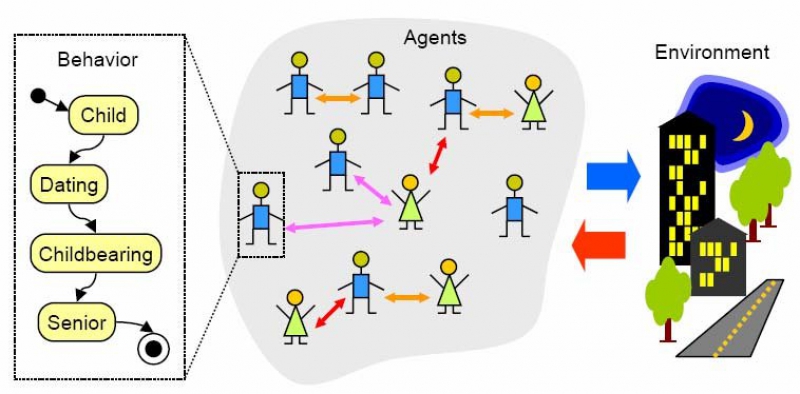
An agent-based model is, simply put, a video game. We create a virtual society where each person lives and takes actions based on their personal principles. It’s not only people; organizations or even countries can be agents. The difference between a scientific model and a game is that the model is based on scientific principles and specific data, while games include more creative input.
Agents may be passive (such as disease carriers) or active: for instance, they might choose to defend or attack. They can produce things, too; the simplest example is of two agents meeting and producing a third. We model their behavior, launch the model and see what happens in different scenarios. The most interesting situations are ones where complex structures emerge from simple principles. For instance, sometimes agents will establish complex economic structures based on simple behavioral principles.
What drawbacks and advantages does this method have?
Surprisingly enough, agent-based models are oftentimes simpler than generalized or population models, because when we model social processes, we can outline the simple rules that drive people. It’s not always clear how these rules transform into what we can observe at the higher, population level, but these models allow us to test our theories. For instance, all people want to maximize their happiness. Depending on their abilities and aspirations, they earn and spend money to extract as much personal benefit as they can. On the population level, we can observe how the economy works, how much people spend on electricity, transport, shopping, etc. The main idea here is how people’s wishes and goals transform and become the process that we observe at a global level.

It can be difficult to explain why this or that sector of economy has grown, but it’s easier to explain why people’s desires have changed; when a new iPhone drops, people become interested in buying one. Such things are more understandable and we can use them to identify basic rules of human behavior. Agent-based modeling was developed to show how, based on very simple rules, we can understand the processes occurring in the society and predict or modify them.
It’s interesting to model irrational behavior. No person dreams of becoming addicted to drugs and dying of an overdose, yet we see that happen in real life. The irrationality here is that people know they’ll regret doing something, but they do it anyway.
One flaw of agent-based modeling is that it requires a lot of data, and specific data at that. It’s usually the data provided by social surveys and experiments because cause-and-effect relations are described at the ethnographic level, at the level of desire and action. It’s hard to get that data. Population data (birth rates, consumer data, transportation, etc.), meanwhile, is easy to acquire, but tough to interpret.
How do you work with data and create models? What kinds of specialists are involved?
We work with ethnographers to study human behavior patterns. For example, they might describe how drug addicts use narcotics; we use that information to build a model and then, based on that model, suggest looking up the data on disease outbreaks. For instance, there are HIV outbreak areas in the USA that have to do with new-generation addicts: they’ve only recently started using drugs and thus haven’t developed any safety habits unlike their more “experienced” peers.

Our theory is that future outbreaks will happen in areas where we can predict an increase in drug addiction rates. Such an increase may occur in places with unfavorable socio-economic conditions, for instance in a town where the factory that has been feeding the population has closed down and left people unemployed. We’ve also seen that in places like this, medical specialists begin to issue more prescriptions for painkillers, which tend to contain opioids. A drug epidemic is likely to follow because people who develop a painkiller addiction are likely to switch to hard drugs. If they begin using heroin, which means intravenous injections, they’ll use syringes, which increases the likelihood of contracting HIV. Based on imitation modeling, we try to develop recommendations for the norms and practices of healthcare in order to prevent future epidemics.
You work with government and commercial projects. Who initiates and sponsors your research on drug addiction?
Most of it is state-sponsored. There is the Substance Abuse and Mental Health Services Administration (SAMHSA), which provides us with financial support. They support a lot of research in this field and report to the US Congress about the need to conduct (and fund) this or that research project, as well as about the treatments or preventative measures that should be used to solve issues. There is also the National Institute of Health (NIH), who are interested in the scientific aspects and providing expertise. The Center for Disease Control and Prevention (CDC) also supports our research related to reducing overdose rates and developing painkiller prescription guidelines.
A few years ago, we worked with the topic of balance between disorder and behavioral components in drug addiction. Cancer, for example, is a diseases that’s generally not defined by human behavior, while drug addicts consciously spend money on drugs, seek out places where they can acquire them, purchase paraphernalia and actively consume drugs. These are all conscious actions made by people in state of moral downfall. We’ve shown that, although the initial consumption of drugs, tobacco and alcohol are purely behavioral actions, regular use of substances causes irreversible changes in the brain. Our common goal with the aforementioned organizations is to stop that process before it becomes irreversible. When a person is already addicted, it’s harder to stop the process. After a long (or not so long) period of consumption “for pleasure” the brain changes its functions, and its desires shift towards increased consumption. Drug addiction becomes a brain disease. For that reason, the researchers’ task is to understand which measures (such as medical products along with social support) can be taken to prevent future complications.

Your team works on a lot of research concerning addiction.
I’m interested in drug addiction as a topic. I think that any mathematical tool can be used in this field. We’ve talked about artificial neural networks, and the human brain contains natural ones; the way they function, react and adapt to narcotics is very interesting. I’ve co-authored a few articles with my friend and colleague Boris Gurkin (Ecole Normale Supérieure de Paris, France) on mathematical modeling of brain processes. We’ve learned how various areas of the brain react to tobacco consumption, to quitting smoking, or to chain smoking.
Since the brain controls our actions, we have to ask: what happens inside it, why does it demand this kind of behavior? Describing these processes is very interesting; we draw parallels between the artificial neural networks that we use to work with Big Data and natural neural networks that form the cognitive process.
In your lecture you mentioned various possible solutions to social issues, such as additional funding for education or the production of medical products. In your experience, which solutions does the government lean towards?
In most cases, medical treatment is the most widespread solution due to political and economical factors. Pharmaceuticals are easier to monitor: they’re produced under strict supervision and research shows that the treatment might not work on everyone, but at least it has none or very little side effects. It is therefore clear that the medicine will be generally successful. That’s why the Food and Drug Administration (FDA) make sure that medicine is manufactured according to regulations, prescribed to patients, and is effective. There are alternative methods, some quite popular, but they’re hard to monitor. I believe that we should do more research on this topic, because the human body is a complex organism and reducing the solution to a single chemical is severe oversimplification.
Preventative measures are important. But it’s hard to assess their effectiveness. If no one falls ill, does this mean that the disease is simply gone or that the measures have worked? If there are no acts of terror, is this because the police are working well or because they simply don’t happen?

How do you understand what causes the increase or decrease in any given occurrence?
We conduct special region-scale research. Let’s say there is a preventative educational program for schoolkids that tells them that smoking and drugs are bad. We pick two regions with similar income rates, social makeup, and tobacco consumption levels. The program is implemented in one region out of the two and, after a while, scientists look at the difference between them. If the program proves to be beneficial, it’s implemented nationwide.
What are the difficulties of working with medical data? Even in the USA, where access to data is said to be open, there are issues with acquiring medical data.
The biggest issue is patient confidentiality. It’s hard to gain access to data even if any identifying information has been redacted. The medical industry doesn’t like sharing. There are a number of pharmaceutical companies, and each studies its own data sets. Nobody wants to share with their competitors or third parties. Sometimes these companies team up with the government and then we get access to insightful data for research.
Another issue, which may not be very obvious, is that medical data is much easier to analyze than it might seem. Many people I know have graduated from MIT or Stanford, developed complex data analysis methods, found work in medical research and found themselves disappointed because in this industry simple models work just as well as complex ones. Intricate algorithms are more useful when you’re working with, say, weather data of complex physical phenomena. In medicine, most processes are simple and linear models handle them well. The basic issues have to do with the quality of data, which must be cleaned up, checked and rechecked. There are also some parameters that are difficult to measure precisely; after all, humans are very complex organisms.
Vasiliy Leonenko, a PhD student at ITMO University’s Institute of Design & Urban Studies, had come to the USA to work with you on a model of influenza virus propagation in St. Petersburg. You’ve worked on that topic with the Research Institute of Influenza about ten years ago; why did the project continue a decade later?

The data we’ve used was actually provided to us by the Research Institute of Influenza. The epidemiological data they have is unique and can’t be found anywhere else in the world. But to gain access, we had to convince them that it wouldn’t be used for any non-scientific, political, or profiteering purposes, but only to further our understanding of the disease and its possible prevention methods. Our research with Vasiliy was successful because the data was provided to him as a Russian scientist and it was used strictly for research; and ITMO University became an important link between the Research Institute of Influenza and RTI International.
Governments are interested in social research; what about commercial clients?
Many companies today take it upon themselves to do socially significant work. The notion is that if the company makes its money from people (like, for example, Coca-Cola), then part of its profits should go back to improving society. We do a lot of work with pharmaceutical companies. A project that my colleagues are working on right now aims to understand what happens to medical drugs after they’ve been sold. A patient gets a prescription, takes it to the pharmacy, buys the drugs, and we don’t know what happens later. We can trace a prescription, but we don’t know how the drugs are consumed, and there is a possibility that some are sold for speculative prices.
Companies are also interested in learning about side effects. They are, of course, studied during clinical trials, but the sample sizes are usually not that big. When people start to use a product en masse, new side effects may appear, and severe ones at that.
What topics does RTI International work with the most these days?
One of the biggest issues is drug addiction. We also have projects on the treatment and prevention of HIV, cancer, diabetes, asthma, influenza, and other illnesses. Most of RTI’s projects concern healthcare.




