
According to research by genetic scientists, some plants and even mammals have whole-genome duplications, i.e. some of their genes exist in several copies that are more or less similar to each other. The ancestral genomes didn’t have such duplicates, but the duplication happened at some point of its evolutionary history and got a foothold in the population.
“Sometimes the genome or some part of it duplicates. At first, it happens incidentally, but this change takes a foothold and stays in future generations, comments Nikita Alekseev, winner of ITMO Fellowship and Professorship program. For example, some chromosome duplicates, and the new copies of genes provide material for the creation of new functions in the process of evolution.”

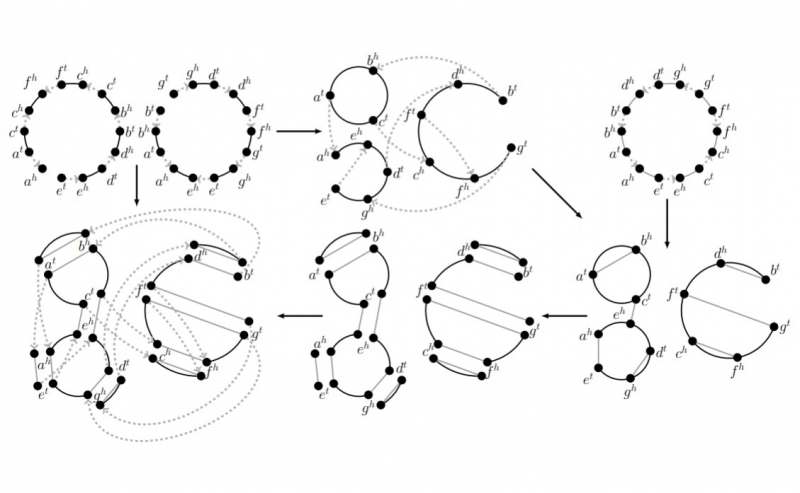
In order to understand the process of genome duplication, it’s necessary to create the evolutionary history with this evolutionary event. The history makes it possible to track what happened to the population in the past and identify where exactly the duplication took place and how in which conditions it secured a foothold. Still, the work on creating such a history is a complex bioinformatics task.
“Collecting genomes and using them to create evolutionary histories is a pretty young field, explains Nikita Alekseev. The problem is that we have imperfect input data that has lots of mistakes and it is necessary to use and combine data that was collected by various means. With the development of technologies that can be used to get high-quality data, there appears a need for the development of new mathematical models and algorithms for their analysis. So, the more we know, the more complex the problem we face. You can say that this is something like a huge crossword puzzle where you don’t even have clues for every mysterious word. At the same time, you occasionally get new data that speaks about more new words, vertical and horizontal.”
Linear programming
When trying to create an evolutionary history of species will whole-genome duplications, a scientist faces a whole series of tasks that serve a similar purpose but have very different mathematical structure. In order to solve them effectively, you need optimization. For this purpose, an international team of scientists that included specialists from ITMO University and the George Washington University (USA) proposed to use integer linear programming approach that were first proposed by Leonid Kantorovich, a Soviet mathematician, economist and the Nobel Memorial Prize in Economic Sciences.
“There’s a class of tasks that are essentially similar but different from the standpoint of mathematics, explains Nikita Alekseev, co-author of the research. So we’ve developed a common approach that comes down to integer linear programming. This is an optimization method that reduces a complex program to a set of linear constraints for which there exists a selection of effective solvers.”

As a result, the scientists developed a program that analyses duplicated genomes and makes presumptions on a species’ evolutionary path, the number of genome duplications that took place in that time, and how the copies of genes that emerge as result of duplication changed. Sometimes mutations take place in them, changes in specific regions, so they are no longer identical.
The new method was tested on yeasts, though it has yet to be used for large-scale biological research. Nevertheless, the authors hope that their algorithm will be interesting to bioinformaticians around the world. The approach can also be applied in studying duplicated genome regions in animals.
“Genome duplications are present in many species and can affect not just the genome as a whole but also its fragments, and our tool can be adapted for solving such problems, too,” concludes Nikita Alekseev.




