Key information about the properties, composition, and behaviors of nanomaterials is often scattered across a given scientific paper. It takes a lot of time and effort to extract this data manually, which complicates large-scale analysis and database creation. This problem can be solved, for example, by using automated data extraction systems. Most available automated systems, however, display a number of limitations: they either work exclusively with texts, require human assistance, or do not process full articles.
As a solution, scientists from ITMO University, in partnership with their colleagues at Lomonosov Moscow State University, have presented NanoMINER – a system that collects data on nanomaterials and nanozymes. The algorithm processes scientific papers, including text, images, and graphs, using a combination of models: in particular, GPT-4o (for text analysis and coherence) and YOLO (for visual data processing).
The system is easy to use and requires no special skills. By uploading a paper into the algorithm, the user obtains structured data on, for instance, the material’s composition as well as synthesis conditions and results; moreover, the system can also predict its type of lattice based on the chemical formula. The automated analysis takes one minute to run, compared to 90 minutes for manual processing.
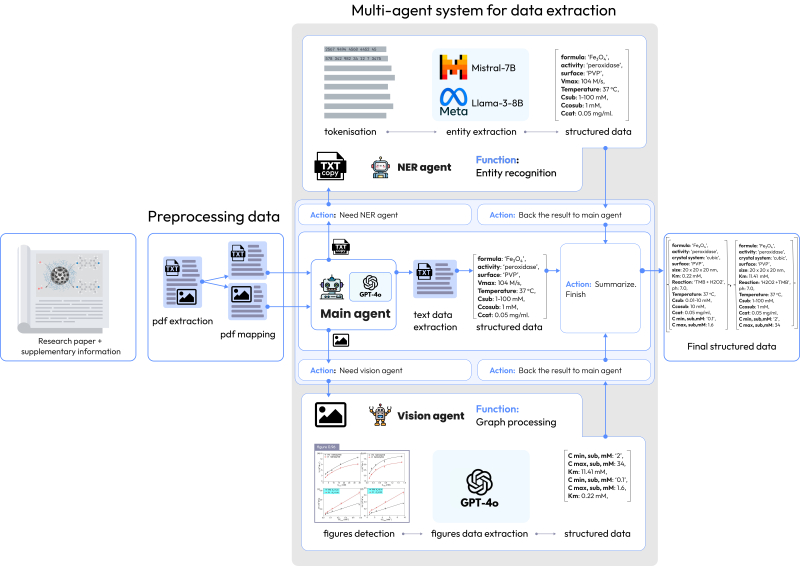
NanoMINER’s operational algorithm. Credit: npj Computational Materials
The researchers tested the model with manually verified data from 20 scientific papers. Among the key criteria were comprehensiveness, accuracy, and coherence of extracted information. The algorithm is shown to recognize data with a high accuracy level of up to 98% for kinetic parameters of nanozymes and up to 66% for molecular characteristics of nanomaterials: chemical formulas, crystal systems, and surface parameters.
NanoMINER is open-source software; its code and setup guides are available via GitHub. Any researcher can download the system onto their PC or server and use it to extract information from any paper. The team claims that their solution will benefit both academic scholars and specialists who deal with nanomaterials, chemical databases, and AI models.
“We’re planning to incorporate new fields of study into our system shortly; these concern nanoparticle toxicity, biocompatibility, catalytic properties, and other crucial properties. At the same time, we also continue to work on the accuracy of our algorithm: we test different architectures of language models – both open-source and commercial API-based ones – to find the best balance between quality and affordability. We’re certain that our software can be adapted for other fields, as well, such as biomedicine. The model can potentially be used to build scalable, self-updating databases,” explains Julia Razlivina, the author of the idea, the co-author of the paper, an engineer at ITMO’s Advanced Engineering School, and an assistant at ITMO’s Faculty of Biotechnologies.

Julia Razlivina. Photo by Artur Ruslanovich
The research is supported by the national program Priority 2030.