
Finding a needle (reference) in a haystack (of text) is a challenge familiar to any scholar who’s ever dealt with adding footnotes to their work. It’s an issue for anyone be they a historian, legal student, or any other adept of humanities. Literary students look for every writer mentioned in many volumes of an author’s correspondence; sociologists count every mention of a politician in thousands of interviews.
Various text-based analysis and search algorithms have been developed over the years. It’s not just about pressing the good old Ctrl + F, but, for example, scouring the text for every proper name or, as text recognition experts call them, “named entities.”

“Mining named entities from texts is far from a new task,” explains Ivan Smetannikov, an associate professor at ITMO University’s Information Technologies and Programming Faculty. “Texts can describe regular real-life objects – a table, a chair, a tree, a ship – that either interact with each other somehow or are simply mentioned. These are just entities. Named entities are ones that have a specific individual name: someone’s full name or address, a name of an organization, the name of a ship. When we say “ship”, we’re referring to an entity; but when it’s “the ship Maria”, it’s a named entity.”
Lost in translation

But, as with everything, there are a number of issues. First of all, the majority of the best such algorithms are developed with the English language in mind. There are fewer algorithms that are suited to the Russian language and they are more difficult to develop due to its complex semantics and morphology. And if an art historian needs to find every address mentioned in an artist’s autobiography, the task becomes even more complicated. This was the challenge faced by an interdisciplinary team of researchers from ITMO University’s Digital Humanities Research Center and Laboratory of Machine Learning.
“We took all of the more-or-less prominent existing solutions designed to mine named entities from Russian-language texts and used them on historical texts. Whereas these models are 95% efficient with contemporary texts, applying them to books, articles, and notes written 60 and more years ago yielded a 70-72% result. And the older the text, the worse the results were,” says Ivan Smetannikov.
As it turned out, a major issue for any algorithm “trained” on contemporary texts are various old-world names such as Theodora, Fevronia, Iolanta, or Mazepa. These proved to be the key pitfalls for the algorithms.

“We proposed additional heuristics that would analyze the extracted material, conduct frequency analysis, and use the results to improve on the extraction parameters,” explains Ivan Smetannikov. “Essentially, we’ve created an additional post-processing unit that would analyze the frequency with which certain words are picked out and decide whether or not the primary algorithm has made a mistake. As a result, the efficiency increased to 78-79%.”
St. Petersburg through the ages
This research initiative was conducted as part of a larger project by the Digital Humanities Center. Its goal is to create an interactive map of St. Petersburg that illustrates the key locations connected to the lives of famous writers, composers, and scientists.
“Our project St. Retrospect is a visualization of culturally significant toponyms in St. Petersburg based on corpus analysis of historical, cultural, and artistic sources,” tells us Antonina Puchkovskaia, head of the DH Center and associate professor at the Institute of International Development and Partnership. “Simply put, we want to create a map where you can see which famous person lived in a certain house in the 19th century and who visited it later. To do that, we need to analyze a massive amount of books, newspapers, biographical dictionaries, and letters. If done by hand, the precision would be as high as it gets, but at a great loss of speed. In a month, one person can read a handful of books and map around a hundred locations and connections. With an algorithm, this task is done many times quicker.”
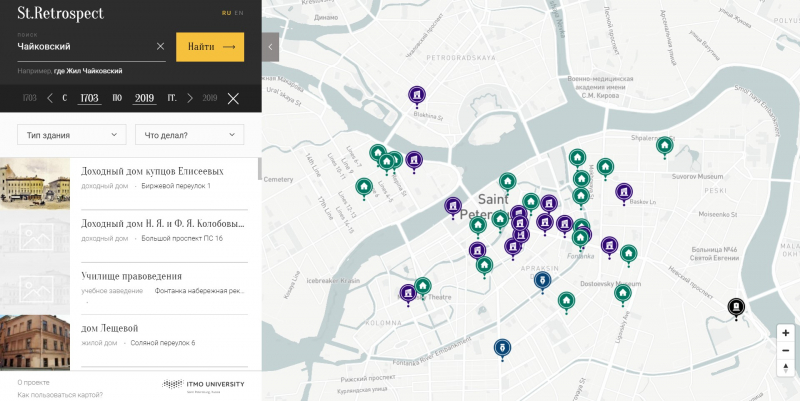
The algorithm doesn’t just extract proper names – it also sorts them into categories such as addresses, last names, or organizations. This too, however, can be an issue. Seeing the name Herzen in the text, the computer can’t always tell if the word refers to the 19th century writer, the street once named after him, or the Herzen University. As the researchers claim, the new and improved algorithm, which exhibits an efficiency of up to 80% even with books from the early 20th century, can analyze several dozen texts in 30 minutes – a task that would take a person several days.





