
Наверное, каждый из нас попадал в такую ситуацию: беседуешь с другом о какой-то книге и вдруг не можешь вспомнить, на какой улице жил главный герой. Открываешь книгу на смартфоне, листаешь, но найти ответ никак не удается, а все варианты, которые вносишь в поиск, дают нулевой результат.
Аналогичная проблема: несколько часов до сдачи курсовой, осталось лишь проставить сноски. Необходимо найти работу, из которой ты взял информацию, но что это за статья или монография? Вспоминаешь, что на что-то похожее ссылался автор другой книги, ищешь эту сноску у него, но поиск в 800-страничном документе занимает долгое время. Практически постоянно с такими проблемами приходится сталкиваться ученым, занимающимся историей, социологией, правоведением и другими гуманитарными науками. Литературовед ищет всех писателей, которых упоминает в своей многотомной переписке автор, социолог считает, каких политиков чаще называют люди в тысячах интервью.
Фото: ITMO.NEWS
Для решения этих проблем уже несколько лет создаются различные алгоритмы анализа и поиска тех или иных слов в тексте. Речь идет не просто о поиске через стандартное сочетание клавиш Ctrl + F, а о сложных алгоритмах, которые ищут в тексте, к примеру, все имена собственные, или, как их называют специалисты по распознаванию текстов, «именованных сущностей».
«Распознавание именованных сущностей в тексте — это давняя задача, — рассказывает доцент факультета информационных технологий и программирования Иван Сметанников. — В текстах у нас могут встречаться просто объекты мира: стол, стул, дерево, корабль, которые могут либо как-то взаимодействовать между собой в тексте, либо просто упоминаться. Это сущности в целом. Именованными сущностями называются такие объекты, у которых есть конкретное индивидуальное обозначение: имя и фамилия человека, адрес, название компании, имя корабля. Когда мы говорим просто “корабль”, то это просто сущность, когда говорим “корабль Мария”, то это уже — именованная сущность».
Трудности перевода

Однако, как водится, существует ряд проблем. Во-первых, большая часть наиболее совершенных алгоритмов такого рода сделана для анализа англоязычных текстов. Для русского языка таких программ меньше, да и сделать их сложнее из-за более сложной семантики и морфологии русской речи. Если же искусствоведу нужно найти все адреса художника в его автобиографии, изданной в 1937 году, то проблема становится еще сложнее. Именно над ее решением работала междисциплинарная команда специалистов в области Digital Humanities и машинного обучения из Университета ИТМО.
«Мы взяли более или менее все крупные существующие решения по извлечению именованных сущностей русского языка и применили для наших исторических текстов, посмотрели на результаты. И выяснилось, что для современных текстов эти модели дают до 95% качества, то на наших текстах (книгах, статьях, заметках), которым было 60 и более лет, результат составил в районе 70-72%. Причем чем старше текст, тем хуже результат», — поясняет Иван Сметанников.
Иван Сметанников. Фото: ITMO.NEWS
Как оказалось, главная проблема для алгоритма, «воспитанного» на современных текстах, заключается в старых именах вроде Феодоры, Февронии, Иоланты или Мазепы. Именно на них точность работы проседала сильнее всего.
«Мы предложили дополнительные эвристики, которые смотрят на то, что извлеклось, проводят частотный анализ и на основе анализа улучшают характеристики извлечения, — говорит Иван Сметанников. — Фактически мы создали дополнительный блок постобработки, который смотрит на частотность определения тех или иных слов и принимает решение относительно того, не сделал ли ошибку основной алгоритм. В результате точность распознавания повысилась до 78-79%».
Исторические адреса Петербурга
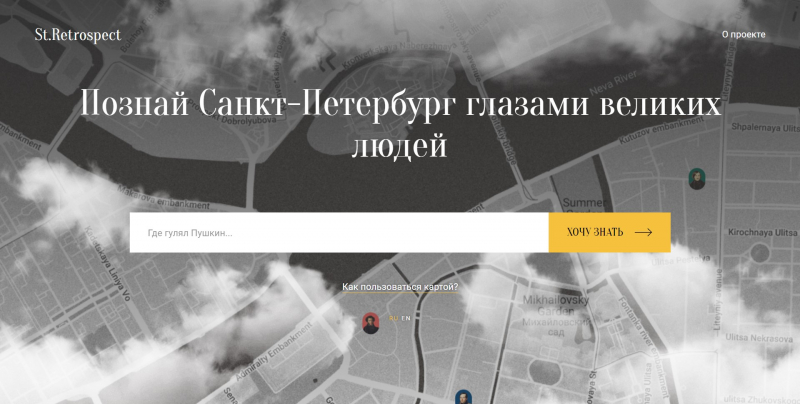
Эта работа — часть большого проекта, который ведет Международный центр цифровых гуманитарных исследований Университета ИТМО. Задача проекта — создать карту важнейших локаций Санкт-Петербурга, которые связаны с именами великих писателей, композиторов ученых.
«Наш проект “St.Retrospect” — это ретроспективная визуализация культурообразующих топонимов Санкт-Петербурга на основе корпусного анализа историко-культурологических и художественных источников, — рассказывает директор центра и руководитель проекта, доцент Института международного развития и партнерства Антонина Пучковская. — Проще говоря, мы хотим, чтобы пользователь мог получить карту, на которой ретроспективно можно узнать информацию о том, кто из известных людей жил в этом доме в XIX веке, а кто здесь бывал после. Для этого надо проанализировать огромную массу книг, газет, биографических словарей, писем. Если это делать вручную, то точность будет максимальной, но скорость при этом страдает очень сильно. Ты можешь прочитать за месяц несколько книг, отметить около сотни локаций и связей. С помощью алгоритма эта работа ускоряется многократно».
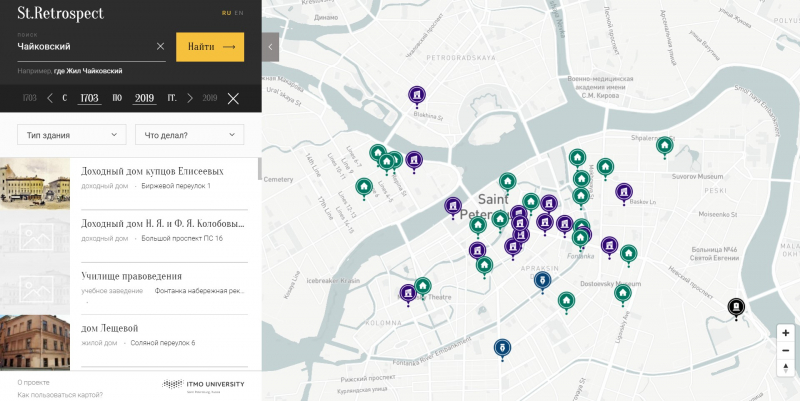
Как утверждают создатели, новый дополненный алгоритм, дающий до 80% правильных поисковых ответов даже на книгах начала XX века, может за полчаса проанализировать несколько десятков текстов. На это у человека ушло бы несколько дней. При этом он не только помечает имена собственные, но и раскладывает их по категориям: адреса, фамилии, учреждения. Это, кстати, добавляет проблем. Не всегда компьютер, «увидев» слово «Герцен» в тексте, легко может понять — речь идет об университете имени Герцена, об улице Герцена или о самом писателе и публицисте XIX века.




