
Lack of algorithms
One of the key challenges in machine learning is dimensionality reduction. Data scientists reduce the number of features by isolating the values among them that have the greatest impact on the result. After this, machine learning models require less memory, work faster and better. The example below shows that eliminating duplicate features increases classification accuracy from 0.903 to 0.943.
|
>>> from sklearn.linear_model import SGDClassifier >>> X, y = make_classification(n_samples=300, n_features=10, random_state=0, n_informative=2) >>> cl1 = SGDClassifier() >>> cl2 = SGDClassifier() |
There are two approaches to dimensionality reduction – feature extraction and feature selection. The latter is more often used in fields like bioinformatics and medicine since it allows you to highlight significant features while preserving semantics, i.e. it does not change the original purpose of features. However, the most common Python machine learning libraries – scikit-learn, pytorch, keras, tensorflow – do not have even a minimally sufficient set of feature selection methods.
To solve this problem, ITMO University students and PhD researchers have developed an open library – ITMO_FS. Ivan Smetannikov, Associate Professor at ITMO’s Information Technologies and Programming Faculty and Deputy Head of the Machine Learning Lab, and his team are working on it. The Lead Developer of the project is Nikita Pilnenskiy, he graduated from the Big Data and Machine Learning Master’s program and has now applied to a PhD program.
“Over the past few years, our laboratory received a lot of requests to solve problems for which the standard tools didn’t fit. For example, we needed ensemble algorithms based on combining filters, or algorithms that take into account the presence of previously known (expertly marked) significant features. Having looked at the existing solutions, we came to the conclusion that they not only did not contain the tools we needed but were also not flexible enough for their possible soft integration. Given the weak competition between such libraries on the market, we decided to create our own library that would fix most of the shortcomings,” says Ivan Smetannikov.
What can the library do?
ITMO_FS is implemented in Python and is compatible with scikit-learn, which is considered the de facto one of the main data analysis tools on Python. Its feature selectors accept the same parameters:
| data: array-like (2-D list, pandas.Dataframe, numpy.array); targets: array-like (1-D list, pandas.Series, numpy.array). |
The library supports all classic approaches to feature selection – filters, wrappers, and embedded methods. Among them are such algorithms as filters based on Spearman and Pearson correlations, Fit Criterion, QPFS, hill climbing filter, and others.
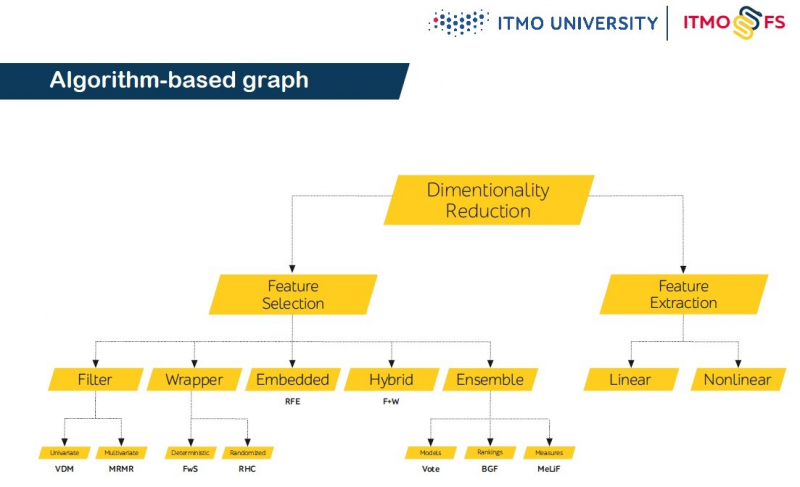
Also, the library supports training ensembles by combining feature selection algorithms based on the feature quality measures used in them. This approach allows us to obtain higher predictive results with low time consumption.
What analogs are there?
There are few feature selection algorithm libraries, especially in Python. One of the major ones is considered to be a project of engineers from Arizona State University (ASU). It supports a large number of algorithms but has hardly been updated recently.
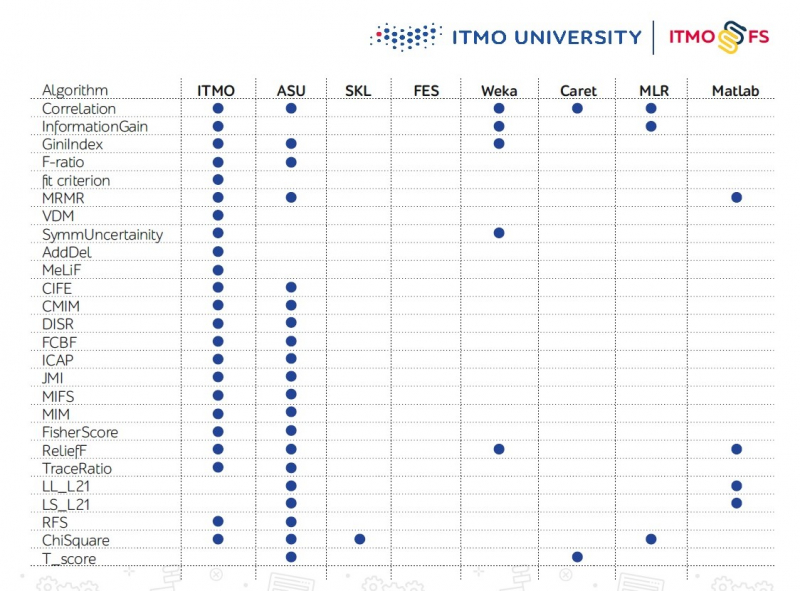
Scikit-learn also has several feature selection mechanisms, but it is not enough.
"In general, over the past five to seven years, the focus has shifted towards ensemble algorithms for feature selection, but they are not particularly represented in such libraries, and that is what we also want to change," comments Ivan Smetannikov.
Project prospects
The creators of ITMO_FS plan to integrate their product into scikit-learn by adding it to the list of officially compatible libraries. At the moment, ITMO_FS already contains the largest number of feature selection algorithms among all libraries, but that is not the limit. Later, there will be an addition of new algorithms, including the team’s own developments.
In the long-term, there are plans to include in the library the meta-learning system, add algorithms for direct work with matrix data (filling in gaps, generating meta-attribute space data, etc.), as well as a graphical interface. Alongside, hackathons will be held using the library in order to interest more developers in the product and get feedback.
It is expected that ITMO_FS will find its use in the fields of medicine and bioinformatics – in such problems as cancer diagnosis, construction of predictive models of phenotypic characteristics (for example, a person’s age), and drug synthesis.
Where can you download it?
If you are interested in the ITMO_FS project, you can download the library and try it out – here is the repository on GitHub. An initial version of the documentation is available at readthedocs. There, you can also see the installation instructions (supported by pip). Any feedback is highly welcomed.



