Зачем вообще предсказывать токсичность материалов
Искусственный интеллект и машинное обучение успешно справляются с различными задачами в органической химии ― например, с помощью алгоритмов специалисты могут предсказывать 3D-структуру белков, различные свойства материалов и создавать лекарства. Однако использовать такие же технологии при работе с наноматериалами гораздо труднее ― это связано со сложностью описания наносистем для алгоритмов. И если предсказывать физические свойства наноматериалов (например, оптические свойства, стабильность в суспензии, некоторые магнитные свойства) удается достаточно хорошо, то успешно рассчитывать их биологические свойства пока не получается.
Между тем наноматериалы и наночастицы активно используются в медицине, в том числе в системах доставки лекарств и диагностических платформах, поэтому уметь предсказывать их биологическое поведение очень важно. Наночастицы взаимодействуют с живыми организмами и, будучи токсичными, могут нанести им вред. Чтобы разработать действительно надежную систему доставки лекарств, необходимо сначала исследовать безопасность этих материалов.
Сейчас уже есть несколько моделей, созданных на основе машинного обучения и позволяющих отвечать на вопрос бинарно ― токсичен материал или нет. Но есть у них и недостатки: алгоритмы не учитывают влияние концентрации вещества. При этом такая информация необходима ученым-экспериментаторам, которые исследуют безопасность наноматериалов опытным путем.
Что придумали в ИТМО
Команда, в которую вошли студенты и сотрудники Центра химии и искусственного интеллекта SCAMT, а также несколько школьников из Петербурга, предложила собственный подход для количественного прогнозирования цитотоксичности неорганических наноматериалов. Метод также основан на алгоритмах машинного обучения, но, в отличие от аналогов, он позволяет воспроизводить концентрационные зависимости, обычно получаемые экспериментально.
С помощью 10–кратной перекрестной проверки ученые установили точность, с которой алгоритм предсказывает токсичность материалов. Погрешность составила 12%, это считается хорошим показателем и не мешает динамике этих процессов.
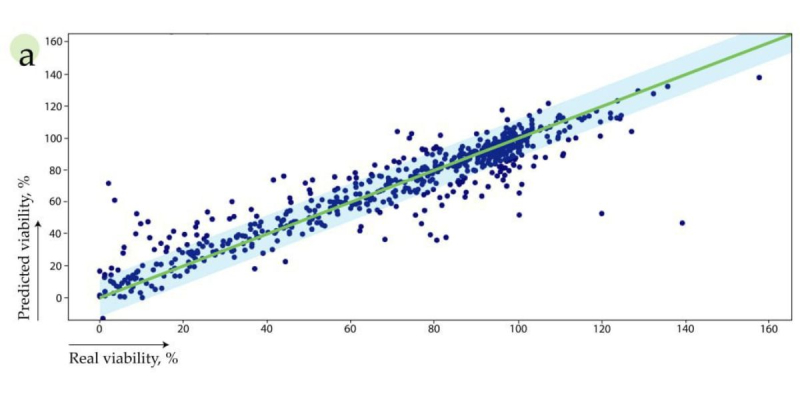
Построенный алгоритм предсказывает токсическое влияние наноматериалов на клетки, учитывая их физико-химические параметры и условия эксперимента. a) Реальные значения выживаемости клеток после обработки наноматериалами сильно коррелируют со значениями, предсказанными моделью. Графики предоставлены исследователями.
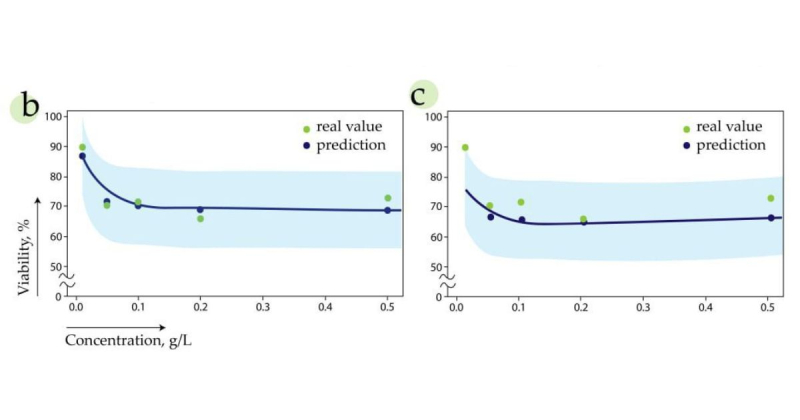
b) Алгоритм позволяет предсказывать целые графики токсичности в зависимости от концентрации наноматериалов, что обычно удается достичь лишь экспериментальным путем. с) Алгоритм успешно воспроизводит эксперимент по предсказанию токсичности даже тогда, когда информация о концентрации вещества отсутствует. Графики предоставлены исследователями.
Где конкретно можно применять алгоритм
Одно из потенциальных применений разработанного алгоритма — скрининг наноматериалов для диагностики и терапии раковых заболеваний на их нетоксичность и безопасность. Наночастицы используются для доставки противораковых препаратов, а также сами могут выполнять терапевтическую и диагностическую роль. Например, некоторые наночастицы могут быть визуализированы на МРТ и помогут обнаружить опухоль на фоне здоровой ткани, выступая в качестве контрастного агента. При этом, разрабатываемые системы могут оказаться опасными и непригодными для применения в реальной практике, что делает подобный скрининг незаменимым.
Как разрабатывали алгоритм
Разработанный алгоритм стал результатом работы на«DataCon», который проводился Центром химии и искусственного интеллекта SCAMT с 19 июля по 1 августа в онлайн-формате. На соревновании участники выполняли различные задачи: собирали и очищали данные, визуализировали их, чтобы выявить зависимости, проводили статистический и графический анализ данных, скрининг моделей для поиска наилучших решений и валидировали результат на разных системах.
На основании проанализированных данных команды разрабатывали алгоритм, который нужно было оформить в виде кода на GitHub — облачной платформе для совместной разработки. Алгоритм победителей хакатона достиг наивысшей метрики по предсказанию токсичности наноматериалов.
Евгения Дин, одна из участниц команды, студентка бакалавриата ИТМО:
«В качестве задания на хакатон мы получили пять датасетов, содержащих информацию о результатах реальных тестов на цитотоксичность наноматериалов. Ключевыми параметрами для описания наноматериалов были химический состав частиц, их диаметр, площадь поверхности, поверхностный заряд, а также параметры самого эксперимента: концентрация наночастиц, время проведения опыта и характеристика самих клеточных линий, на которых ставился эксперимент. Мы объединили датасеты и проанализировали имеющиеся данные на предмет наличия нежелательных корреляций и выбросов, отрицательно влияющих на работу моделей машинного обучения. Для построения регрессионной модели по предсказанию выживаемости клеток при взаимодействии с наноматериалами мы выбрали метод градиентного бустинга (CatBoostRegressor) — он заключается в последовательном построении ансамбля слабых моделей (например, деревьев принятия решений). После построения рабочего алгоритма мы проверили его работу путем вывода опорных параметров, участвующих в процессе принятия решения».
При принятии решений алгоритм следует логике экспериментаторов и обращает внимание на то, как каждый из параметров системы влияет на итоговую токсичность. Графики предоставлены исследователями.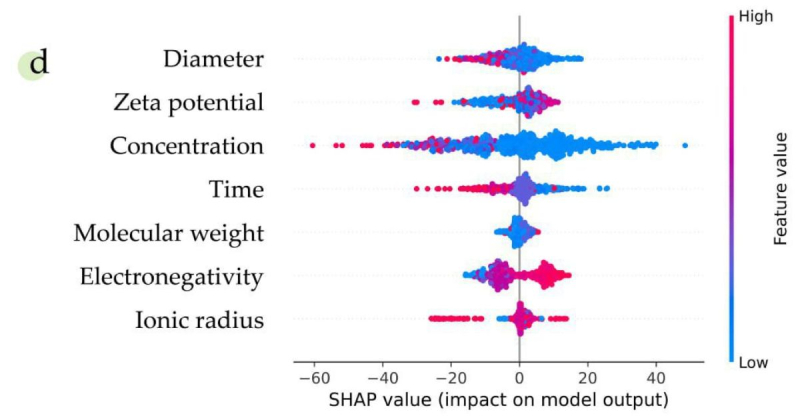
Кто в команде проекта
В команду вошли студенты бакалавриата ИТМО Николай Широкий, Евгения Дин, Софья Сиротенко, аспирантка химико-биологического кластера Юлия Разливина, а также ученик 11 класса Аничкова лицея Илья Петров и ученик 10 класса 373 лицея Юрий Сергин. Руководили проектом аспирант химико-биологического кластера Никита Серов и директор химико-биологического кластера Владимир Виноградов.
Что дальше
Ученые из Центра искусственного интеллекта в химии — одного из подразделений химико-биологического кластера ИТМО — планируют объединить разработанный алгоритм с другими разработками Центра химии и искусственного интеллекта в единый проект, представленный в виде веб-сайта. С его помощью можно будет предсказывать токсичность, магнитные, каталитические и другие свойства наноматериалов. При его разработке исследователи вдохновляются Materials Project — открытым ресурсом, который позволяет рассчитывать свойства материалов для их дальнейшего применения преимущественно в физике. Ученые Центра химии и искусственного интеллекта считают одной из своих целей повышение доступности подобных решений для экспериментаторов.
«Наша задача — максимально встроить этот алгоритм в другие наши разработки, чтобы, помимо предсказания целевых свойств по типу каталитической активности, эффективности доставки, мы могли предсказывать безопасность материалов. Это важно, потому что алгоритмы могут предложить очень эффективную каталитическую систему, которая при этом в количестве 1 мкг на литр будет убивать 100% клеточных линий. Для научного сообщества в целом мы планируем разработать веб-сайт, на котором представим собранный и очищенный набор данных, чтобы другие ученые могли использовать его в своих разработках. Важно, чтобы исследования были воспроизводимы и валидны, поэтому мы выступаем за открытость таких ресурсов», — рассказал один из руководителей проекта Никита Серов.
Никита Серов. Фото: Маргарита Ерукова / ITMO.NEWS
Статья: Nikolai Shirokii, Yevgeniya Din, Ilya Petrov, Yurii Seregin, Sofia Sirotenko, Julia Razlivina, Nikita Serov, Vladimir Vinogradov. Quantitative Prediction of Inorganic Nanomaterial Cellular Toxicity via Machine Learning (Small, 2023)