― О необходимости внедрять новые технологии для общественного здоровья говорят уже давно и не только в связи с пандемией. Если более конкретно, о каких технологиях речь и как они помогут решить проблемы?
― Технологии общественного здоровья ― очень широкое понятие. Но важно понимать, что прежде всего они посвящены профилактике наиболее социально значимых заболеваний. Основных групп таких заболеваний три:
- сердечно-сосудистые заболевания,
- онкологические заболевания,
- широкие вопросы, касающиеся демографии ― повышение рождаемости, рост качества акушерско-гинекологической помощи, снижение детской смертности.
Цель технологий общественного здоровья ― обеспечить своевременную диагностику и профилактику, чтобы предупредить развитие заболевания, затормозить его развитие или назначить лечение еще на ранней стадии, когда шансы на полное выздоровление высоки. Эти задачи решаются совокупностью методов ― как собственно медицинскими, организационными методами, так и с помощью цифровых технологий, включающих в себя технологии искусственного интеллекта. И именно последним направлением мы занимаемся в ИТМО.
Безусловно, пандемия внесла свои коррективы, но и до нее все понимали, что население стареет, и нагрузка на систему здравоохранения будет только расти. Поэтому уже сейчас необходимо вводить методики автоматизации медицинской помощи, чтобы обеспечить помощью максимальное количество людей, действительно в ней нуждающихся.
Анна Андрейченко. Фото: Дмитрий Григорьев / ITMO.NEWS
― Что подразумевает такая автоматизация?
― Я уже упоминала о необходимости проведения раннего скрининга. К сожалению, как известно, часто заболевания не проявляют себя сразу, у человека нет жалоб, он никуда не обращается. Так можно прожить несколько лет и прийти к врачу уже слишком поздно, когда заболевание дорастет до таких масштабов, что вылечить его полностью будет уже довольно сложно.
Поэтому необходимо своевременно выявлять проблемы в том числе у бессимптомных пациентов. Но делать это непросто ― такие профилактические исследования требуют очень много ресурсов и создают нагрузку на систему здравоохранения, ведь врачам надо протестировать огромное количество людей, интерпретировать результаты десятки тысяч исследований, чтобы из бессимптомных выделить тех, у кого действительно есть проблемы. Во-вторых, где в принципе найти столько врачей, которые правильно и качественно пересмотрят такой массив исследований, из которых 99% без отклонений? И тут даже дело не в профессионализме и экспертизе врача ― у любого может банально замылиться глаз.
Искусственный интеллект, технологии автоматизации как раз и могут помочь в решении этих проблем. В частности, за счет внедрения систем автономной интерпретации исследований, например, рентгенологических снимков. Буквально год назад первая такая разработка получила регистрацию в Европе. Но подчеркну, что такие системы не выявляют патологию ― они нацелены на то, чтобы, исходя из своей базы знаний, отсеять снимки, на которых нет патологических объектов, и сфокусировать врача именно на те случаи, где есть определенные подозрения. Это поможет сделать программы скрининга более масштабируемыми.
― Что делается в этом направлении в России? Я знаю, что вы принимали участие в эксперименте по использованию технологий в области компьютерного зрения для анализа медицинских изображений, который запустили в Москве. Каким был результат этого проекта?
― Я работала над этим проектом с 2019 по 2022 год и на первом этапе непосредственно руководила формированием научно-технологических подходов. Главная задача проекта заключалась в том, чтобы провести научно-практическое исследование возможности использования в системе здравоохранения Москвы методов поддержки принятия решений на основе результатов анализа данных лучевой диагностики. И я бы сказала, что это единственный на данный момент проект в стране, где так активно и разносторонне внедряются технологии компьютерного зрения в области медицинской диагностики. Интересен этот опыт и в международном масштабе. Объясню почему.
Данные по эксперименту по использованию инновационных технологий в области компьютерного зрения для анализа медицинских изображений и дальнейшего применения в системе здравоохранения города Москвы. Источник: mosmed.ai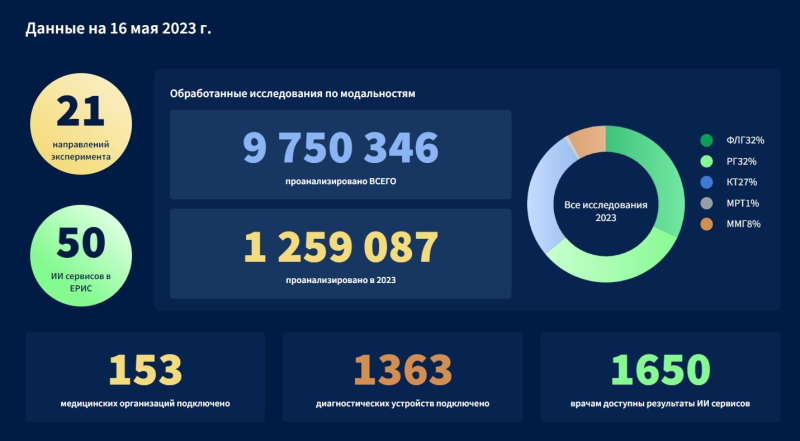
Дело в том, что в Москве создан единый радиологический информационный сервис, который объединяет все отделения лучевой диагностики города, подведомственные департаменту здравоохранения Москвы. Эта система ежедневно получает более 30 тысяч исследований ― данные поступают со всех поликлиник города. И поэтому, подключив алгоритмы компьютерного зрения к такому сервису, мы могли за очень короткий промежуток времени на огромном количестве снимков, то есть фактически на уровне популяции, прогнать их работу в режиме реального времени.
Аналогичных по масштабу сервисов в мире очень мало. Что-то похожее есть разве что в Китае, про аналогичные сервисы в Европе и США я пока не слышала.
Проект еще продолжается, но на первом его этапе мы уже показали, что в принципе возможно анализировать такой объем снимков в режиме реального времени, при этом делать это достаточно надежно, без технологических дефектов. Задача следующего этапа ― продемонстрировать клиническую ценность алгоритмов. Но мы уже подготовили технологическую базу, которая обеспечивает своего рода конвейер по оценке алгоритмов ИИ, по их подключению, тестированию, мониторингу технических параметров их работы и так далее.
― Как конкретно результаты проекта смогут облегчить врачам их ежедневную работу?
― Во-первых, главное преимущество от использования систем автоматизации ― более быстрая постановка диагноза, ведь снимки можно анализировать гораздо быстрее. Во-вторых, это помогает унифицировать и стандартизировать процесс.
Рентгенология завязана на достаточно субъективном восприятии. Если вы дадите один и тот же снимок двум разным врачам, вы почти всегда не получите одинаковую интерпретацию. И это не только российская проблема, во всем мире для унификации создаются различные медицинские онтологические словари, стандартизированные базы знаний и формы отчетов о результатах интерпретации. Машина унифицирует эти процессы за счет того, что она оперирует конкретными данными и сравнивает каждый снимок с эталоном. Для того, чтобы вывести такой эталон, нельзя опираться на мнение только одного специалиста, нужно учитывать дополнительные исследования или добиваться консенсуса врачей. И мы, когда готовили наборы данных во время нашего эксперимента, как раз и добивались формирования такого консенсуса по каждому исследованию.
Прочитайте также:
Как в ИТМО готовят специалистов в области Public Health Sciences
― Тем не менее, медицинское сообщество достаточно консервативно. Как эксперимент восприняли сами врачи? Как в принципе повышать доверие к таким технологиям в сообществе?
― Вопрос сложный. Всегда нужно начинать с проработки недоверия и обучения. Такая система не должна быть для врачей «черным ящиком». Кроме того, зачастую присутствует и, своего рода, иррациональный страх: «Вот есть искусственный интеллект, некий живой организм, который что-то сказал или вообще пришел меня заменить». Нет, нужно прежде всего понимать, что это просто компьютерная программа, которая оперирует конкретным набором данных и выявляет определенные взаимосвязи. И тогда становятся понятны ее ограничения.
Нужны лидеры мнений, которые покажут пример сообществу. И наконец, безусловно, должна быть выстроена регуляторика.
В конечном счете ответственность несет врач. И в том числе поэтому многие специалисты говорят: «Не нужен мне ваш искусственный интеллект». Если ты несешь персональную ответственность за результат, рискуешь своей репутацией, профессией, конечно, ты пойдешь пересматривать и проверять то, что выдала машина. Поэтому должны быть выстроены регуляторные режимы, закрепляющие ответственность.
Если эта автономная система, то ответственность за ошибку, я считаю, в том числе должен нести производитель этой системы. Разработчикам тоже нужно осознавать ответственность за свои продукты и последствия их некорректных срабатываний.
Фото: National Cancer Institute / Unsplash
― На каком уровне проработки эти вопросы сейчас в России?
― По этике ИИ в медицине в России пока сделано мало. Одним из лидеров этого направления можно назвать Сбербанк. В этом году в Москве разработали 10 ГОСТов для тестирования искусственного интеллекта, в том числе в здравоохранении. Но в плане этики и безопасности искусственного интеллекта в России и во всем мире вопросов еще очень много.
― Недавно в ИТМО была создана новая лаборатория «Цифровые технологии в общественном здоровье», которую вы возглавили. Какие главные цели и задачи перед собой ставите?
― Лаборатория была создана в ноябре 2022 года в рамках Национального проекта «Наука и университеты» по направлению «Новая медицина». И главное, что хотелось бы отметить, ― мы не собираемся разрабатывать новые модели искусственного интеллекта, мы ставим своей целью создавать технологии, которые обеспечат надежное внедрение и эксплуатацию систем на основе искусственного интеллекта на практике.
Сейчас мы собираем систему из микросервисов, которые решают задачи по формированию набора медицинских данных. И в этой системе предстоит решить много вопросов ― прежде всего, как обеспечить интеграцию с медицинскими организациями, то есть настроить все интерфейсы так, чтобы данные можно было эффективно собирать и хранить в одном месте.
Естественно, поликлиники не могут позволить себе держать в штате дата-инженера, это вообще не их задача. А мы, будучи частью ИТМО, ведущего IT-вуза, как раз можем помочь медикам эти технологии для них сформировать. При этом мы не навязываем врачам какие-то готовые сервисы ― медицинские специалисты вовлекаются в проекты на самых ранних этапах, именно они формируют запрос. Это позволит создавать продукты, которые действительно будут потом востребованы в практике.
Команда лаборатории «Цифровые технологии в общественном здоровье». Слева направо: экономист здравоохранения Арсен Давитадзе, научный коммуникатор и администратор лаборатории Арина Ускова, медицинский физик и руководитель лаборатории Анна Андрейченко, пульмонолог Ника Пушкина и специалист в области информационной безопасности Станислав Кондратенко. Фото: Мария Бакина / Мегабайт Медиа
― Какие конкретно продукты вы планируете создать?
― Конкретно сейчас мы уже разрабатываем систему для технологического сопровождения программы по скринингу рака легкого. Эту программу в прошлом году организовал в Петербурге онколог Андрей Нефедов из НИИ пульмонологии. Он проделал огромную работу ― полностью продумал методологию, привлек партнеров, скоординировал ход программы, но данные собирались не автоматически, а при ручном сборе всегда велик риск возникновения ошибок ― банально можно перепутать ID участника скрининга, из-за чего результаты будут представлены некорректно.
Мы вышли с предложением создать систему, которая будет автоматически принимать на себя ID участника скрининга, подцеплять результаты первичных исследований, направлять снимки на пересмотр врачам-экспертам, систематизировать информацию и предоставлять обзорную аналитику врачу-организатору программы скрининга, чтобы он, например, быстро понимал, сколько у него участников исследования, где нужно что-то доработать, пересмотреть. Пока эта система заточена на решение одной задачи ― скрининг рака легкого. Но мы изначально делаем все модульно, чтобы впоследствии систему можно было адаптировать и под другие цели.
ИТМО ― университет открытого кода, и мы также работаем в open source. Поэтому впоследствии мы планируем выложить результаты в открытый доступ, чтобы их могли дорабатывать и использовать все, кто заинтересуется. Мы предполагаем, что результатом этого пилотного проекта будет не только подтвержденная целесообразность проведения такого скрининга с клинической точки зрения, но и отработанная технология, оптимизирующая процессы проведения скрининга. А впоследствии эту программу можно будет масштабировать и запускать в городе.
План работы лаборатории до 2024 года. Источник: dpht.itmo.ru/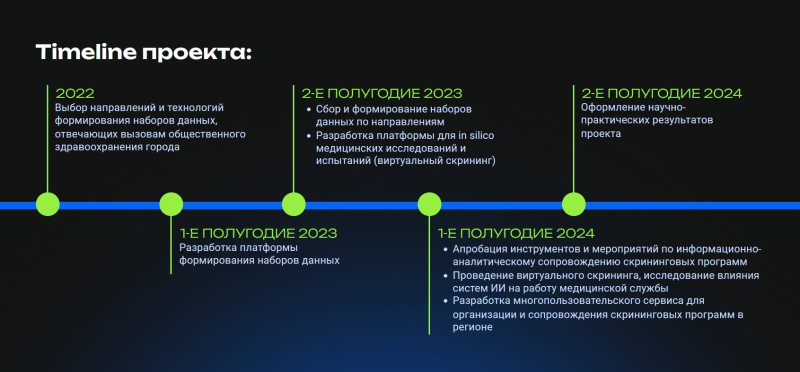
― На какие сроки рассчитана работа?
― По этому проекту мы планируем представить MVP летом 2023 года. В целом же работа лаборатории обусловлена сроками госзадания ― это 2022–2024 годы. Но мы надеемся, что этим не ограничится, потому что как минимум эту, уже создаваемую систему мы можем использовать и для других целей ― например, для скрининга рака молочной железы.
Дело в том, что когда врач направляет, например, на КТ (компьютерную томографию), у него стоит четкая задача ― найти или не найти на снимке признаки конкретного заболевания, по которому есть подозрения. Например, определить процент поражения легких при ковиде. Но в область исследования попадает и сердце, и сосуды. И вся эта информация доступна на снимках, но чаще всего она не интерпретируется, не вносится в протоколы. Автоматизированные системы анализа снимков могут помочь трансформировать эту работу и дополнительно посмотреть, есть ли подозрительные узелки в легких, возможные расширения сосудов, что-то еще. У врача просто нет ресурсов, чтобы скрупулезно просматривать на снимке всё (а в среднем одно КТ-исследование легких состоит из 300–500 снимков!). У машины ― есть, она может выявить и подсветить вам неограниченное число биомаркёров, которые потенциально могут привести к опасным заболеваниям.
По этому направлению мы в том числе будем работать с НМИЦ онкологии им. Н.Н. Петрова. Мы планируем агрегировать уже имеющиеся в распоряжении центра снимки и тестировать имеющиеся системы ИИ на предмет выявления таких биомаркёров. В дальнейшем это позволит оценить наиболее перспективные системы для выявления патологий и рекомендовать городу, какую систему лучше подключить.
Анна Андрейченко. Фото: Дмитрий Григорьев / ITMO.NEWS
― В лаборатории междисциплинарная команда. Кто еще в нее входит, помимо врачей?
― В такой специфической области, как медицина, интердисциплинарность должна быть на всех этапах ― от постановки задачи до использования моделей. Если говорить об общественном здоровье, помимо врачей и разработчиков в команде обязательно должны быть эпидемиологи, потому что правильные наборы данных мы можем собрать только в популяционном контексте. Эпидемиологи могут определить распространенность заболевания, посчитать конечную клиническую ценность систем искусственного интеллекта, сказать, какая выборка пациентов нам нужна, как правильно сделать дизайн исследования. А еще у нас есть команда научных коммуникаторов и социологов. Такие специалисты очень важны, поскольку область новая, и необходимо на всех этапах работать с участниками процесса ― как врачами, так и пациентами ― для повышения их осведомленности о возможностях цифровых технологий в медицине.
― А попасть в команду к вам можно?
― Сейчас у нас много разработчиков-стажеров. Мы заинтересованы в том, чтобы ребята приходили к нам учиться, делать дипломные работы, участвовать в комьюнити. Также мы открыты к сотрудничеству с медицинскими организациями и врачами, которые видят ценность в автоматизации и придут к нам с конкретным запросом.