Процесс перевода занимает несколько минут: за это время нейросети «Яндекса» успевают вычленить из речи текст, перевести его, синтезировать русскоязычный голосовой перевод и подогнать его под скорость видео, чтобы не было рассинхронизации. А еще определить пол говорящего с помощью методов биометрии и выбрать подходящий вариант голоса. При этом, по задумке, должны быть сохранены все характеристики естественной речи: эмоциональность, интонации, паузы, правильные разбивки на фразы.
О разработке технологии ITMO.NEWS поговорил с Андреем Законовым, экс-руководителем продукта «Алиса» и «Умные устройства», выпускником кафедры «Компьютерные технологии» (сейчас ― факультет информационных технологий и программирования) Университета ИТМО. Он предложил идею переводчика видео и запустил работу над проектом в компании.
― Андрей, расскажите, как все начиналось, как вообще пришла такая идея?
― Новый продукт начинался в нашей команде «Алисы» и «Умных устройств», которой я тогда руководил. Сначала мы собрали первый прототип, затем постепенно подключали коллег из других направлений и набирали уже выделенную команду под проект. Я был его участником вплоть до тестового запуска в июле этого года. Сейчас работу над продуктом продолжают ребята из «Яндекс.Браузера», а я занят новым проектом в другой компании. Так что могу рассказать про продуктовую идею и как работали над технологиями до бета-запуска, а про актуальный статус и следующие планы у меня уже нет информации.
На самом деле очень похожие задачи мы решали в команде «Алисы». Нам нужно было сделать так, чтобы «Алиса» понимала, что говорит человек, ― причем максимально быстро, за доли секунды. За это время нужно распознать речь и преобразовать ее в текст, вычленить суть, интерпретировать и понять вопрос, найти нужную информацию в интернете или сторонних сервисах ― и в итоге сгенерировать это в голосовой ответ. Задача очень сложная, мы в команде решали ее на протяжении нескольких лет и в итоге достигли таких «около-реалтайм» скоростей, что разговор с колонкой приближается по уровню удобства к разговору с живым человеком.

Андрей Законов. Фото: «Мегабайт Медиа»
В то же время в команде «Яндекс.Переводчика» уже научились в режиме реального времени переводить предложения с английского на русский, причем с хорошим качеством. И тут важно понимать, что это не перевод отдельных слов: нейросеть учитывает контекст, целые фразы и куски текста.
Поэтому, когда мы в очередной раз думали, в какую сторону можно было бы развивать эти технологии, у меня как раз и возникла идея автоматического перевода видео. По сути, все необходимые для этого технологии уже были. Мы очень хорошо умеем распознавать текст и речь, внутри «Яндекса» есть хороший переводчик, над синтезом речи мы много работали в команде «Алисы» ― чтобы она звучала максимально человечно, с эмоциями, правильными интонациями.
Оставалось решить, как сделать процесс перевода максимально удобным для пользователей, собрать из этих технологий законченный продукт. Чтобы пользователям, условно, не нужно было заходить на отдельный сайт, кидать туда ссылку на видео, ждать, когда видео обработается, и так далее. Тут как раз и подключились ребята из «Яндекс.Браузера» ― это было максимально логичным решением, внутри которого можно было собрать все наши фичи.
― Вы упомянули про эмоциональность синтезированной речи ― а как это вообще делается? Откуда нейросеть знает, с какой интонацией нужно прочитать текст?
― На самом деле это довольно большая история, которую мы только начали развивать. Изначально мы задумывали, что нужно повторять эмоции людей из оригинальной звуковой дорожки. Это то, что по сути делают профессиональные переводчики и актеры дубляжа. Смотреть видео с переводом должно быть приятно и комфортно ― там должны быть эмоции, интонации, паузы и так далее.
По тексту эмоцию понять невозможно. Ведь есть ирония, сарказм, искренняя радость, раздражение и прочее. Поэтому эмоцию надо научиться определять по оригинальной аудиодорожке. Но важно отметить, что это, скорее, уже следующий шаг.
― А откуда берутся эмоции в синтезированном голосе? У «Яндекса» есть база слов, прочитанных актером с разными интонациями?
― Просто прочитать все слова не получится, все сложнее. Иначе актеру надо было бы начитать вообще все слова в русском языке ― это огромная работа. К тому же регулярно появляются новые слова, новые технические термины или наименования. Или можно привести в пример «Яндекс.Навигатор» ― существует бесчисленное количество названий населенных пунктов, улиц, топонимов и так далее.
Поэтому все устроено иначе: работа идет не на уровне слов, а на уровне фонем или даже частей фонем, которые можно склеивать и получать слова и предложения. Эмоции в голос также добавляются на постобработке. Одну и ту же фразу можно сгенерировать с разной эмоцией. Ускорить или замедлить синтезированную речь, чтобы подогнать ее под скорость видео, — это тоже делается на постобработке.

Технология style transfer. Иллюстрация: Thushan Ganegedara / Towards Data Science
В качестве примера приведу технологию style transfer, весьма популярную в области обработки изображений. Любую фотографию можно превратить в картину в духе Ван Гога или Сальвадора Дали ― получается такое накладывание определенного стиля на изображение. В случае голоса можно делать нечто похожее: обучить модели на датасете с весело или грустно сказанными фразами и получить возможность переносить определенную эмоцию на синтезированную речь.
Это очень интересное направление в сфере речевых технологий, но пока что оно только в начале пути.
― Как биометрия «участвует» в определении эмоций говорящего на видео?
― В текущей версии биометрия используется только для определения пола, чтобы выбрать один из двух голосов, мужской или женский. Следующий интересный шаг ― добавлять больше голосов и учиться отличать разные голоса одного пола. Ведь у каждого голоса есть свой отпечаток, узнаваемые черты и характеристики, почти как черты лица.
В этом плане мы запускали классную фичу в колонках: если с «Алисой» говорит ребенок, она это понимает и начинает вести себя по-другому. Автоматически ставит возрастные ограничения на контент, выбирает более веселые и смешные ответы, чаще общается на «ты», а не на «вы».
― А есть какие-то проблемы в технологии, которые пока что не удалось решить?
― Я очень много экспериментировал с разными видео в ходе работы. Есть жанры, где эта технология пока работает недостаточно хорошо. Примеры, где ей уже очень комфортно пользоваться: один спикер что-то рассказывает в формате лекции, несколько спикеров беседуют в формате интервью. А вот с кейсами, где очень много сленга или эмоций, технология не справится. Например, популярный сейчас жанр стриминга игр как раз относится к таким. Там очень много специфических слов, резких бессвязных выкриков. Или некоторые видеоблоги, которые люди обычно ведут очень эмоционально.
Также не всегда оптимально технология работает в случаях, когда одновременно разговаривают много людей, перебивают друг друга. В итоге они все будут озвучены одним голосом, и всё это сольется в трудно понимаемую речь.
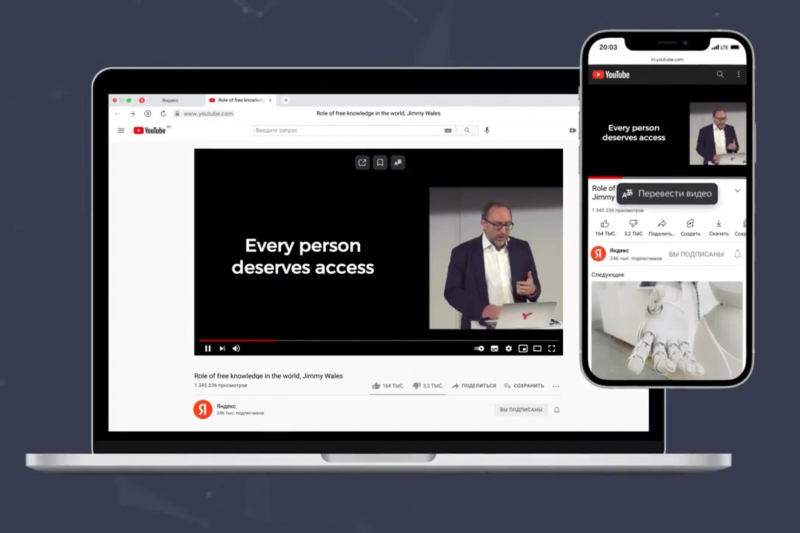
Как работает закадровый перевод видео в «Яндекс.Браузере»
― Почему такая технология появилась именно для русскоязычного сегмента? Почему крупные ИТ-корпорации не сделали это раньше?
― Тут совпало много факторов. Во-первых, в англоговорящих странах эта технология менее интересна, ведь контента на английском в разы больше, чем на любом другом языке. Плюс сейчас самый правильный момент для появления такой технологии. Еще пять лет назад user generated content ― то есть видеоконтента, созданного и залитого в интернет самими пользователями, ― было принципиально меньше. Десять лет назад такая потребность даже не существовала, потому что большая часть видеопродукции была профессиональной ― на ее производство тратили много денег, поэтому готовили также и профессиональный перевод.
Сейчас же каждый день появляются тысячи качественных видео на разных языках, переводить их с той же скоростью невозможно и экономически невыгодно. Это долгая и сложная работа.
Действительно, у нас, как у русскоговорящей аудитории, есть большое желание смотреть контент на английском. И большая потребность в нем. Даже если смотреть на чисто образовательный контент, который лично меня интересует и вдохновляет более всего, то в любой сфере — в ИТ, искусстве, в других областях ― информации на английском в сотни раз больше.
При этом, по опросам ВЦИОМ, свободно английским языком владеет около 5% населения. То есть очень мало кто может посмотреть на языке оригинала лекцию из Гарварда или Стэнфорда. А смотреть видео с субтитрами бывает сильно неудобно ― гораздо приятнее слушать лекции с аудиопереводом на фоне.
И последний важный фактор. Если все начинать делать с нуля, то нужно огромное количество технологий: распознавание голоса, его синтез, биометрия, перевод. Тут как раз совпало, что у «Яндекса» все эти технологии уже есть. Более того, их активно применяли в разных продуктах, они были готовы к продакшен-использованию с большими нагрузками. В мире существует мало компаний, у которых все эти технологии есть, да еще и на таком высоком уровне.



