Группа ученых ИТМО создала модель нового алгоритма для анализа смысла текста. В нем, помимо традиционных для нейронных сетей категорий вроде частотности использования слов, также вводится категория субъективности восприятия текста. Что это значит для будущего ИИ и при чем тут квантовая теория — обо всем этом подробнее в материале ITMO.NEWS.
Анализ текстов. Источник: digitaltrends.com
Искусственный интеллект давно превосходит человеческий по многим параметрам. С середины XX века машина умеет считать несравнимо быстрее любого математика. Еще в 1997 году компьютер победил гроссмейстера Гарри Каспарова* в шахматном матче. В 2016 году два изобретателя — Джей Флэтлэнд и Пол Роуз — опубликовали видео, где созданный ими робот собирал кубик Рубика всего за одну секунду. На тот момент лучший результат человека составлял почти пять секунд.
Сейчас компьютерам подвластны такие задачи, как написание текстов и музыки. В начале прошлого года суд впервые признал подлежащим защите авторским правом текст, написанный искусственным интеллектом. Машина практически идеально справляется с логическими задачами, с математическим анализом, со сбором данных и компиляцией на их основе своего контента.
«Большие нейронные сети обучают на огромных массивах текстов, или изображений, или мелодий, в зависимости от задачи, — объясняет старший научный сотрудник национального центра когнитивных разработок Университета ИТМО Илья Суров, — чтобы в связях этой нейронной сети отразились определенные закономерности. Используя их, машина может компилировать свои тексты, изображения или, скажем, предполагать, какое следующее слово человек хочет вбить в строчке поиска. Но это работает не везде. На сложных задачах, когда нужно принять решение, не похожее на ранее изученные примеры, когда нужна нетривиальная аналогия, компьютер пробуксовывает, несмотря на огромные вычислительные мощности».
Илья Суров. Фото Маргариты Еруковой
От простого к сложному
Группа ученых ИТМО совместно с коллегами из Швеции, Италии и Франции создала модель, которая анализирует текст иначе, не как традиционная нейронная сеть, которая, по сути, сравнивает его с уже изученными ею ранее сочетаниями слов. «Наша идея была в том, чтобы сконструировать смысл письменного текста так, как это делает человек, имитировать наше с вами понимание текста», — поясняет первый автор работы Илья Суров.
Для начала исследователи попытались научить машину искать связь между двумя понятиями, которые есть в тексте. При этом так, чтобы компьютер делал это по тем же схемам, что и человек.
«Как правило, в науке, чтобы решить сложную задачу, связанную с каким-то эффектом, сначала обращаются к самой простой, в которой уже виден этот эффект, — рассказывает Илья Суров, — так же и мы сфокусировались на самом простом акте восприятия текста. В нашем случае это выявление связи между двумя разными словами в тексте. К примеру, “солнце” и “дерево”, “продвижение” и “сайт”».
Квантовая нейрофизиология восприятия
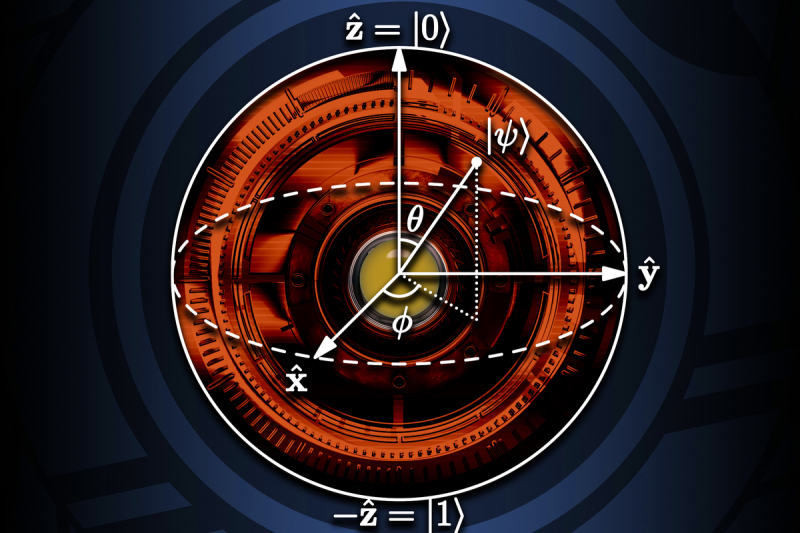
Чтобы решить эту задачу, ученые отказались от классической нейронной сети и обратились к квантовой теории. В своей модели самый простой акт понимания текста они уподобили возбуждению группы нейронов в мозгу человека. Как в электромагнитной волне, такое возбуждение имеет амплитуду и фазу. Эти показатели сложно выразить в традиционном двоичном коде при помощи битов, но можно передать с помощью их квантового аналога — кубита.
«Для наглядности представьте себе отрезок, у которого на концах “0” и “1”, это и будет бит, — объясняет Илья Суров, — но у него может быть лишь одно состояние из двух: либо “0”, либо “1”. А теперь представьте себе сферу, у которой эта линейка — диаметр, соединяющий два полюса — северный “1” и южный “0”. Это и будет кубит. При этом у него может быть не два состояния, а намного больше. Его состояние может соответствовать любой точке на поверхности этой сферы. Широта соответствует амплитуде, а долгота — фазе нейронного возбуждения».
Кубит. Источник: infoworld.com
Квантовые алгоритмы на классических компьютерах
Несмотря на то, что кубиты используются в прототипах квантовых вычислительных систем, построить их модель можно и на самом обычном компьютере — точно так же, как любой ноутбук справится с построением трехмерной модели Земли или футбольного мяча. Чтобы задать состояние этой модели кубита, нужно ввести лишь несколько чисел.
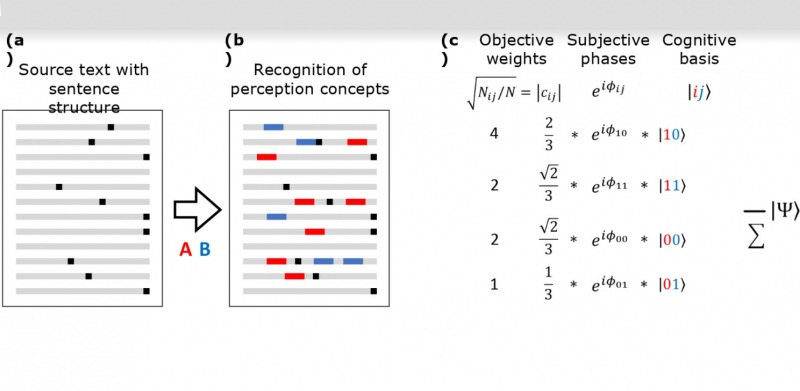
«Благодаря этому нам сразу открываются для использования инструменты, которые разработаны в квантовой теории, — продолжает Илья Суров, — к примеру, теория квантовой запутанности, не имеющая аналогов в классической информатике. Она описывает свойства парной системы, которые не сводятся к свойствам ее частей. Например, смысл словосочетания “продвижение сайта” не равен сумме смыслов слов “продвижение” и “сайт” по отдельности. В нашей модели такая корреляция связывает два нейронных возбуждения в процессе восприятия текста, а запутанность — это смысловая связь между соответствующими словами. Мы берем текст, строим по нему двухкубитное состояние восприятия пары слов и вычисляем для этого состояния квантовую запутанность. Результат описывает смысловую связь слов в тексте».
Схема работы алгоритма. Изображение предоставлено авторами статьи
Шаг к человекоподобному интеллекту
Такая система способна куда глубже понимать смысл естественного языка и выявлять связи, основанные не только на статистике встречаемости слов.
«Новизна нашей модели в том, что результат ее предсказания не один, это некий диапазон возможных решений, — отмечает Илья Суров, — и этот диапазон определяется сразу двумя основными характеристиками смысла. Первая — объективная статистика словоупотреблений, которая учитывается и классической нейронной сетью. Вторая характеристика — роль человека в создании смысла. То, что нельзя сказать однозначно, глядя на текст. Любой текст лишь задает диапазон возможностей, в котором конкретный смысл определяется читателем. Один человек поймет написанное одним образом, а другой — другим. Наш алгоритм позволяет это учитывать».
Илья Суров. Фото Маргариты Еруковой
По словам Сурова, введение подобных категорий — это один из первых шагов на пути к созданию человекоподобного искусственного интеллекта, который невозможен без учета субъективного компонента смысла. Моделирование мышления человека на принципах квантовой теории открывает возможности для построения принципиально новых алгоритмов обработки информации.
Ilya A. Surov, E. Semenenko, A. V. Platonov, I. A. Bessmertny, F. Galofaro, Z. Toffano, A. Yu. Khrennikov & A. P. Alodjants. Quantum semantics of text perception. Scientific Reports, 2021/10.1038/s41598-021-83490-9