Нулевая гипотеза и P-value
Сейчас довольно тяжело представить ситуацию, когда современное научное знание может быть признано обществом, научным сообществом, институтами без доказанного статистического бэкграунда.
Но так было не всегда — строгое требование подтверждать гипотезы и теории эмпирическими данными стало считаться обязательным совсем недавно. Еще в середине прошлого века существовало множество влиятельных теорий в социологии, экономике, психологии, которые были теориями в чистом виде. Самый известный пример — теория Зигмунда Фрейда о психоанализе. Она оказала огромное влияние на культуру, общество и науку, при этом сама была создана при отсутствии каких-либо экспериментов, проверок, четких эмпирических данных.
Если же сегодня посмотреть на структуру типичной научной статьи, мы обязательно найдем в ней некое эмпирическое исследование с сопутствующей математической обработкой.
Допустим, ученые, например, биологи или врачи, хотят проверить какую-то гипотезу: у них есть десять пациентов, которых они хотят исследовать, и на основании этой небольшой выборки они планируют сделать какое-то научное высказывание обо всей генеральной совокупности. Вначале они должны выдвинуть нулевую гипотезу — это предположение, которое формулируется как отсутствие различий, отсутствие влияние фактора, отсутствие эффекта.
Допустим, эти ученые изобрели новую вакцину, эффективность которой они хотят проверить. Нулевой гипотезой будет предположение, что новая вакцина будет работать с той же эффективностью, что и плацебо, то есть пустышка. Дальше эти ученые проводят тесты, наблюдают и сравнивают полученные данные со своей нулевой гипотезой. Они видят, что в выборке людей, на которых тестировалась вакцина, на 20% больше выздоровевших, чем в плацебо-группе. Учитывая, что испытуемых в выборке было очень мало, можно заявить, что это всего лишь совпадение, случайность или влияние скрытых, неизвестных факторов.
Но математики придумали такой трюк: несмотря на то, что выборка всего одна и она весьма мала, мы все равно можем предположить, как вела бы себя изучаемая реальность, если бы мы проводили не один эксперимент, сделали бы не одну выборку, а бесконечное их количество. Можно представить самую простую аналогию: на доске для игры в дартсе вокруг центра всегда очень много следов от попаданий, а чем дальше от центра — тем их меньше. Даже несмотря на то, что ни одна попытка попасть в цель не удалась, если мы усредним все эти попытки, то все равно окажемся где-то очень и очень близко к центру доски.

То, что мы сделали один эксперимент или кинули дротик один раз, нам ничего не говорит. Но мы можем предположить, как бы выглядело распределение этих бросков нашего эксперимента в изучаемой реальности. И дальше происходит несложная математика, которая просто позволяет нам показать, насколько хорошо наблюдаемый результаты согласуются с нашей изначальной гипотезой.
В случае с вакциной исследователи при полученных ими эмпирических данных вполне могут отказаться от нулевой гипотезы и заявить, что их вакцина работает, потому что вероятность получить прирост выздоровления в 20% случайным образом очень и очень мала. Такой метод подтверждения или опровержения гипотезы называется P-value или P-значение — вероятность получить для данной вероятностной модели распределения значений случайной величины такое же или более экстремальное значение статистики (среднего арифметического, медианы и др.), по сравнению с ранее наблюдаемым, при условии, что нулевая гипотеза верна.
Статистика и проблемы современной науки
Подавляющее большинство современных научных публикаций и вообще представление о том, что такое научное знание, базируется на одном из основных критериев — статистической достоверности. Особенно справедливо это в случае каких-либо эмпирических исследований.
Статистика помогает нам отличать науку от ненауки, понимать, правильные это данные или неправильные, можно им верить или нельзя. Другое дело, что те же самые статистические методы, просто неверно истолкованные, используют и различные лженаучные исследователи — и это является огромной проблемой.
Всю современную статистику, по сути, заложили два человека — биологи и математики Карл Пирсон и Рональд Фишер. Они придумали практически всю методологию, которую мы сегодня используем: теорию корреляции, теорию распределения, алгоритмы принятия решений и множество других методов.
Вся статистика отвечает на один общий вопрос: если наша нулевая гипотеза верна, то какова вероятность получить такие же результаты или еще более выраженные, то есть насколько хорошо наблюдаемая эмпирическая реальность согласуется с нулевой гипотезой. Это основополагающее определение того, как статистика проверяет вопросы окружающего мира.

Во всем современном академическом сообществе применяется золотой стандарт — магическое правило, что P-value должно быть меньше 0,05. Если наше P-value меньше 0,05, то мы считаем это основанием отклонить нулевую гипотезу и принять альтернативную.
P-value стал социальным элементом в науке — на его основании принимается множество важных решений: обнародовать ли результаты исследований для широкой общественности, публиковать ли их в научном журнале, выделять ли ресурсы на проведение дальнейших экспериментов и т.д.
Например, серьезные рецензируемые журналы отдают предпочтение тем работам, в которых были получены значимые результаты, то есть P-value меньше 0,05. И это породило массу проблем в современном научном знании, потому что система подстроилась под те правила игры, в которую ее заставили играть. Принуждение исследователей получать статистически важные результаты привело к тому, что те сами стали отказываться от своих работ, которые не прошли этот порог в 0,05, перестали сдавать их для публикации. Хотя, очевидно, что это равноценное знание — подтвердилась гипотеза или не подтвердилась. Отрицательные результаты не менее, а чаще и более важны, чем положительные.
Вторая весьма серьезная проблема получила даже специальное название — p-hacking. Даже в самых рецензируемых журналах, таких как Nature, регулярно происходят большие скандалы из-за того, что ученые, чтобы их работы были опубликованы, допускали различные манипуляции с цифрами, чтобы получить пороговую P-value.
Самое смешное, что этот порог появился почти случайно. Цифра в 0,05 была взята из ранней работы Пирсона, в которой он писал примерно следующее: «P-value в целом нам не говорит, насколько знание является верным или неверным. Это некоторая математическая величина, доказывающая чисто математическое обоснование правильности гипотезы.Число 0,05 можно принять за условный порог, но в целом полностью опираться на него смысла нет». Как это часто бывает, люди запомнили только цифру, а остальной контекст забылся. И на многие годы P меньше 0,05 стал таким ключевым элементом статистики. Оно используется даже в софте, программах, работающих со статистикой: в них зашито, что если P больше 0,05, то все, работа не научна, результаты не доказаны.

Решит ли проблему отказ от статистических методов
Но как понять, что статистику применили правильно и результатам можно верить? Мы неизбежно попадаем в ловушку: как только мы ввели правила игры, система начинает под них подстраиваться. Всегда найдутся люди, которые вместо того, чтобы честно отправлять только те результаты, где статистика была применена максимально правильно и показала необходимый P-value, пытаются эту систему обмануть. Подобные скандалы возникают на самых высоких уровнях современной науки.
Какого-то понятного решения у этой проблемы нет. С одной стороны, иногда слышатся предложения, вроде того, что давайте полностью отменим такую концепцию, при которой необходим какой-то порог, пусть ученые публикуют все как есть — такая идиллическая идея open science. Главное — идея, а статистика — это уже детали. Это левый край шкалы, который действительно возникает в качестве оппозиции к деспотичному правилу, которое довольно долго господствует в научных журналах.

Но эту идею довольно тяжело реализовать. Понятное дело, что какой-то порог входа все же должен быть. Поэтому пытаются придумать новый подход: давайте оставим концепцию порога входа, но будем играть честно. Например, сейчас все больше и больше набирает популярность идея, что при публикации научной статьи необходимо прилагать все данные, все логи, по которым производились расчеты, вплоть до скриптов, на R, на Python, других языках программирования, которые позволяли бы любому другому человеку эти результаты воспроизвести. Понятно, что человек, который просто нарисовал себе нужные цифры, с трудом сможет пройти такой порог. Но проблема в том, что как только придумываются новые защиты, находятся и новые способы их обойти.
Поэтому ученые идут еще дальше — они предлагают помимо всего перечисленного еще и заранее писать, какие гипотезы предполагалось проверить. То есть перед тем, как опубликовать статью в каком-то журнале, исследователи говорят: мы сейчас проводим эксперимент в лаборатории, в котором мы хотим проверить разные гипотезы. Проблема в том, что это почти всегда лукавство: обычно у исследователей уже есть какие-то наработки, уже полученные минимальные результаты, но преподносятся они как чистые гипотезы. Опять же, это объясняется чисто социальными факторами.
Не новость, что финансирование науки осуществляется через систему грантов. Как это работает? Исследователь пишет заявку на грант, в которой расписываются все гипотезы и ожидаемые результаты. По итогу работы составляется отчет об успешности или неуспешности проверки гипотезы.
Так уж сложилось, что большинство всех отчетов носит чисто положительный характер: что изначально заявили, то и получилось. Ровно по тем же самым причинам, что и в случае с публикациями в журналах — негативные данные там принимаются неохотно. Получается, что вроде дали человеку или научному коллективу какую-то внушительную сумму, они год работали, а в результате не получили ничего, кроме опровержения всех своих гипотез.

С точки зрения научного знания это абсолютно нормальная ситуация, так бывает в 99% случаев. Прорывное открытие — это следствие многих лет работы и тысячи неудачных попыток. Но как только мы сталкиваемся с каким-либо социальным институтом, сразу становится тяжело признаваться, что у нас ничего не вышло.
Это очень сложная проблема, из которой тяжело выбраться, но, тем не менее, мы хотя бы подошли к этапу, когда начали говорить об этой проблеме. Современная наука вообще испытывает в данный момент серьезные потрясения. Например, недавно разгоревшийся кризис воспроизводимости классических экспериментов 70 — 80-х годов в психологических и социальных науках. Эта одержимость науки недавнего прошлого публиковать только хорошие, положительные результаты и привела к такому кризису.
Сейчас акцент с обсчитывания всевозможных статистических данных смещается именно к репликации полученных результатов, повторению эксперимента другими специалистами в других условиях. Только так можно убедиться в том, что полученное знание действительно объективно. Это правило хорошего тона, которое в будущем, скорее всего, станет обязательным условием для научных публикаций. Потому что идея, что объективность можно измерить всего лишь одним P-value — это, конечно, иллюзия.
Это одна из самых больших проблем на сегодняшний день, с которой все борются. Сейчас даже появились журналы, которые вообще запрещают публиковать результаты с P-value, отказываясь от нее в пользу баесовской статистики, которая в последнее время набирает все большую популярность.
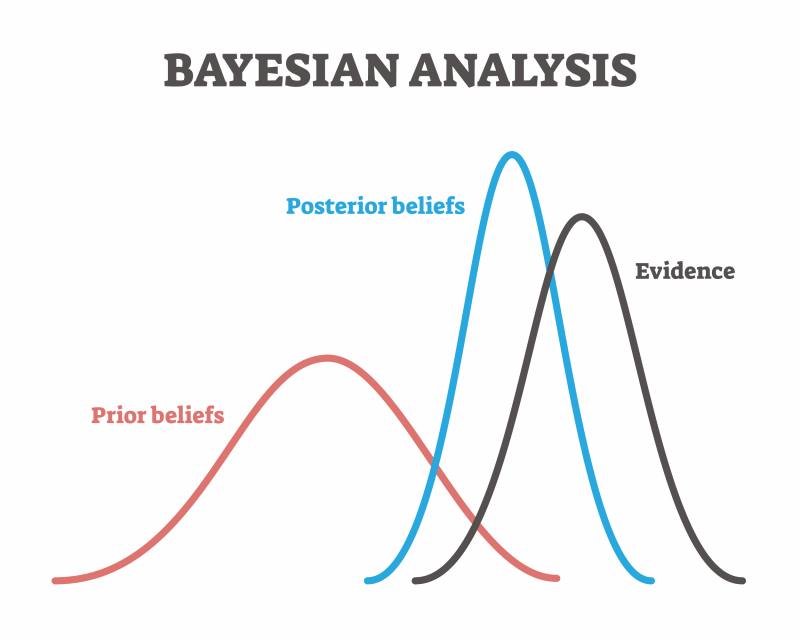
Баесовская статистика — это метод подсчета обоснованности гипотез и предположений на основе имеющихся доказательств в виде данных и эмпирических наблюдений. Проще говоря, достоверность гипотезы зависит от того, насколько сильно она объясняет существующие факты. Чем больше вариантов объяснения фактов, тем менее достоверна гипотеза.
Если P-value довольно абстрактный способ измерения научности знания, он не проверяет вероятность гипотез, то Байесовская статистика, по мнению некоторых, считает более правильно.
Наука и лженаука
Как сейчас проверяется объективность научного знания и степень доверия к нему? Первая, самая высокоуровневая концепция, подразумевает вопрос: вписывается ли знание в современную научную картину мира? Второй вопрос — корректно ли было проведено исследование? Третий — корректно ли обработаны данные? И четвертый — корректно ли обработаны данные третьими лицами, удалось ли воспроизвести результат. Последнему пункту сейчас придается особенное значение.
В РАН есть целый отдел, который занимается псевдонаучными исследованиями. Это огромная и очень важная проблема, ведь псевдонаука — это не просто что-то неправильное, но еще и потенциально вредное для людей и окружающего мира.
Возникает вопрос, как разграничить научное и ненаучное знание? У Карла Поппера была целая концепция классификации научного знания, он считал, что научным может считаться только то знание, истинность которого может быть опровергнута. Это называется принципом фальсифицируемости — и он противоположен принципу верифицируемости: при верификации гипотезы исследователь ищет подтверждающие ее примеры, при фальсифицируемости — примеры, опровергающие ее.
Это и есть самый главный принцип научности, а вовсе не статистическое подтверждение. Например, теория психоанализа так сильно критиковалась именно потому, что в классическом понимании эту теорию очень тяжело опровергнуть.



