
Сотрудники Международной лаборатории «Компьютерные технологии» Университета ИТМО Арсений Нериновский и Игорь Бужинский заняли 73 место на соревнованиях Jigsaw Multilingual Toxic Comment Classification, которые проводились дочерней структурой Google. Это уже третий по счету турнир, участники которого должны были научить алгоритм искать токсичные комментарии в общем массиве данных, отличая их от нейтральных и доброжелательных записей. Лучшие 5% участников получают на турнире золото, а лучшие 13% — серебро. Таким образом, команда ИТМО оказалась среди обладателей серебра.
Турнир проходил весной-летом 2020 года на популярной площадке Kaggle.com. В нем приняло участие около 1500 команд со всего мира.
«Соревнования никак не связаны с тем, чем я занимался до этого, — рассказывает Арсений Нериновский. — Мы с Игорем ранее вместе работали над статьей, тут у обоих было некоторое количество свободного времени и мы решили поучаствовать в каком-то турнире на Kaggle. Мы выбрали этот, потому что там можно было тренировать трансформеры, которые очень требовательны к ресурсам. В повседневной жизни у нас доступа к таким ресурсам нет, но Kaggle предоставляет бесплатный доступ к вычислительным мощностям, так что мы решили попробовать».

«Трансформеры — это разновидность глубоких нейронных сетей, предложенная в статье Attention Is All You Need в 2017 году, — рассказывает доцент факультета информационных технологий и программирования Иван Сметанников. — По факту она решает задачу кодирования-декодирования и, в частности, может очень эффективно быть применена для решения задачи машинного перевода. Одна из особенностей конкурса, в котором участвовал Арсений, была в том, что тренировочная выборка для моделей была представлена на английском языке, а валидационная и тестовая выборки ― на других языках. Эта и некоторые другие особенности конкурса потребовали использования подобных моделей».
Тренировка нейросети

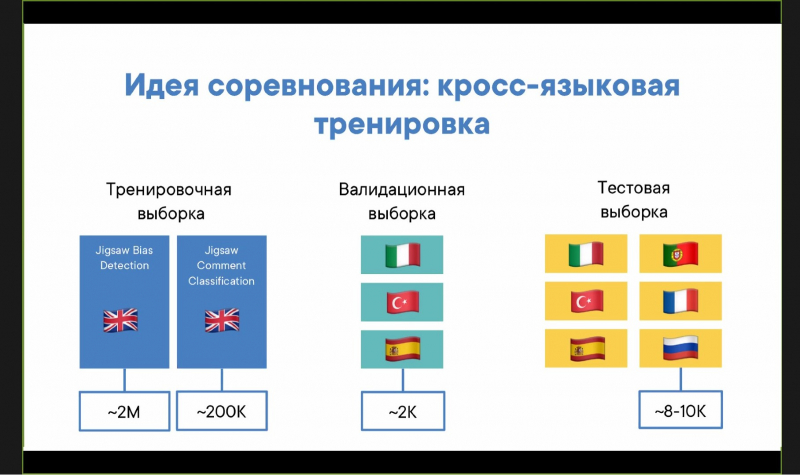
Всего у участников было более двух месяцев на решение соревнования. В качестве тренировочного материала организаторы выдали им данные прошлых соревнований — порядка 2 миллионов английских комментариев для тренировки и 8000 комментариев на трех языках для валидации. Эти комментарии были заранее размечены как токсичные или нетоксичные. Отработав ту или иную гипотезу, участники должны проверить свой алгоритм на тестовой выборке, которую также предоставили организаторы. Она состояла уже из 60 000 комментариев на шести языках. В ней также были представлены токсичные и нетоксичные комментарии, но они уже не были размечены. Результат проверки отсылался организаторам, которые автоматически проверяли его и заносили баллы в таблицу в соответствии с результатом.
«Суть в том, что в многоязычном контексте легко собрать выборку на одном языке, но дальше собрать большее количество выборок на нескольких языках сложно, — объясняет Арсений Нериновский. ― Допустим, в российской соцсети легко собрать выборку на русском, а вот на украинском и казахском — сложнее, потому что найти людей для разметки сложнее, чем просто на русском. Поэтому такая конфигурация данных — тренируете на одном языке и работаете на многих — популярна».
Тренировка нейросети происходит в два этапа. Сначала идет предтренировка, когда авторы алгоритма загружают в нейросеть большое количество обычных текстов на разных языках. Условие одно — это должен быть связный текст, написанный живым человеком.

«В этих текстах вы пропускаете случайным образом слова, модель должна учиться их предсказывать. Так она понимает логику языка. Дальше наступает очередь собственно тренировки, когда вы обучаете модель искать токсичные комментарии, отличая их от нетоксичных, используя в этом как раз "понимание" логики языка, заложенное во время предтренировки», — объясняет Арсений Нериновский.
После этого нейросеть готова искать токсичные комментарии не только в тексте изначального языка, взятого для тренировки, но и на других.
«На самом деле в этом нет ничего удивительного, ведь если подумать, то все люди на планете мыслят довольно схожим образом независимо от языка, на котором они говорят, — поясняет Иван Сметанников. — Языки могут довольно сильно отличаться, но в конечном счете скрытый за ними посыл неизменен. Конечно, подобное утверждение может показаться несколько грубоватым, поскольку на него накладывается культурный фон, внутренние коннотации и множество других языковых особенностей самих языков, но, думаю, что общая идея ясна. В некотором смысле это свойство эксплуатируется с помощью техники трансфера знаний (Transfer learning), когда мы обучаем языковую модель на одном языке, а потом дообучаем и используем на другом. Обычно данная техника используется в ситуации, когда у вас на руках имеются огромные размеченные корпуса текстов языка-донора и практически отсутствуют оные для языка-реципиента».
Путь к серебру
Перед участниками соревнований не было никаких ограничений. Они могли взять любой трансформер и тренировать его на любой выборке, не обязательно предложенной организаторами. Участники могли свободно искать информацию о том, как эта проблема решается в научных статьях и реальных подразделениях интернет-компаний. Более того, на форуме конкурсанты обсуждали те или иные подходы прямо во время турнира.
Несмотря на то, что команда из Университета ИТМО участвовала в этих соревнованиях в первый раз, она достаточно быстро попала в «серебряную» часть турнирной таблицы, где располагались лучшие 5% команд.
«Трансформеры сильно зависят от их состояния в начале тренировки и от порядка подачи данных при тренировке, — рассказывает Арсений Нериновский об одном из методов, позволивших показать хороший результат. — Мы обучали несколько раз модель с одной и той же стартовой точки и делали из этих моделей ансамбль. Простая методика, но, как нам показалось, она добавила некоторые очки за счет стабилизации трансформера».
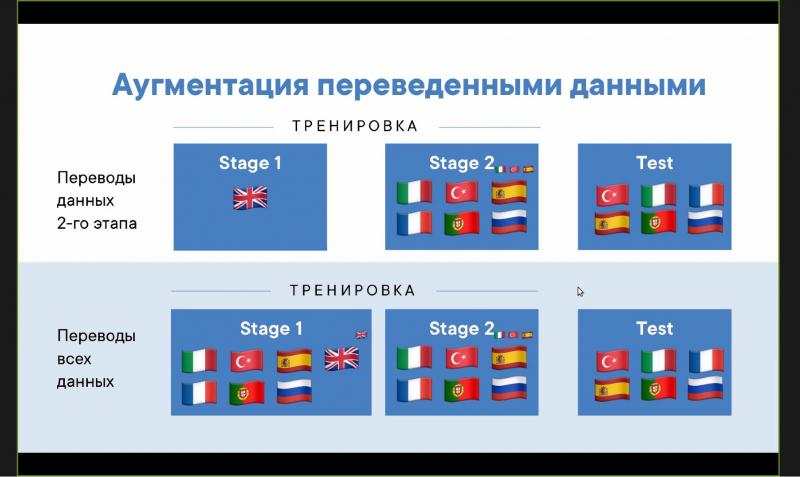
Некоторые участники переводили предложенную организаторами выборку с английского на другие языки через автоматические переводчики. Команда ИТМО также прибегла к использованию переводных данных, но с осторожностью.

«Тут есть проблема детоксификации — токсичный английский комментарий, переведенный на русский, становится гораздо менее токсичным. Таковы принципы современных переводчиков, — рассказывает Арсений Нериновский. — Мы сфокусировались на переводах меньше. Когда мы использовали переведенные данные, то только одна модель успешно сработала».
При этом, как признаются участники, они занимались соревнованиями в свободное от учебы и науки время, поэтому оценивают результат как неплохой.
«Я в это время писал магистерскую, Игорь занимался какой-то статьей, — поясняет Арсений Нериновский. — В результате мы сделали порядка 96 посылок. У тех, кто попал в ТОП-10, было порядка 300–400 посылок».
Результаты соревнований и опыт, полученный на них, Арсений Нериновский представил на VK Tech Talks ITMO.




